本文假设你是一个刚接触web3的数据分析师,开始组建你的 web3 分析团队,或者刚刚对 web3 数据产生兴趣。无论采用哪种方式,你都应该已经大致熟悉了 APIs、数据库、转换和模型在 web2 中的工作方式。
在这本新指南中,我将尽量简明扼要地阐述我的三个观点:
思考:为什么开放的数据渠道会改变数据发挥效用的方式
工具:web3 数据栈中的工具概述,以及如何利用它们
团队:web3 数据团队的基本考虑和技能
让我们先总结一下如何在 web2 中构建、查询和访问数据(即访问 Twitter 的 API)。我们有四个步骤来简化数据渠道:
触发 API 事件(发送了一些推文)
更新到数据库(连接到现有的用户模型/状态更改)
特定产品/分析用例的数据转换
模型训练和部署(用于管理你的 Twitter feed)
当数据是开源的时候,唯一需要的步骤是在转换完成之后。Kaggle(1000个数据科学/特征工程竞赛)和 hugs Face(26,000 个顶级 NLP 模型)等社区使用一些公开的数据子集来帮助企业构建更好的模型。有一些特定领域的情况,比如在前面的三个步骤中开放数据的开放街道地图,但是它们仍然有写权限的限制。
美地方法官已将SEC诉Ripple案移交至治安法官办公室:金色财经报道,美国证券交易委员会(SEC)诉Ripple案的下一阶段即将推进,美国纽约南区地方法院法官Analisa Torres于7月17日提交了文件,将该案移交治安法官(Magistrate Judge)办公室,法官Sarah Netburn将监督接下来的审理阶段。
根据法院发布的“经修订的治安法官移交令”,下一步将是一般预审,包括时间安排、证据开示、非决定性预审动议和和解。[2023/7/18 11:00:39]
我想声明的是,我只是在这里谈论数据,我并不是说 web2 完全没有开源。像大多数其他的工程角色一样,web2 数据有大量的开源工具来构建他们的管道(dbt, apache, TensorFlow)。我们仍然在 web3 中使用所有这些工具。总之,他们的工具是开放的,但他们的数据是封闭的。
Web3 也将数据开源,这意味着不再只有数据科学家在开放环境下工作,分析工程师和数据工程师也在开放环境下工作!每个人都参与到一个更连续的工作流程中,而不是一个几乎是黑盒的数据循环。
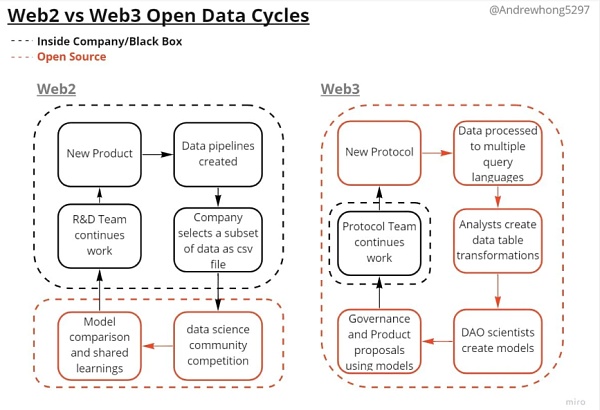
工作的形式已经从 web2 数据大坝到 web3 数据河流、三角洲和海洋。同样重要的是需要注意,生态系统中的所有产品都会同时受到这个循环的影响。
历史上的今天丨美国纽约南区地方法院对Bitfinex和Tether提起集体诉讼:2019年10月7日,美国纽约南区地方法院对Bitfinex和Tether提起集体诉讼。根据公开文件,原告指控Bitfinex和Tether通过Tether投资者、操纵市场和隐藏非法收益。起诉书的第一、第二和第三项指控Bitfinex和Tether违反《商品交易法》中市场操纵行为规定;第四项指控违反了《谢尔曼反垄断法》(Sherman Act against the Tether),称“被告Tether控制了美国和世界上80%以上的稳定币市场,从而赋予了Tether“垄断权力”;第五项指控违反了联邦RICO法令,该法最初是为了打击有组织犯罪;第六项指控称被告存在欺诈行为;第七项指控违反了纽约的贸易惯例法。[2020/10/7]
让我们看一个 web3 分析师如何一起工作的例子。有几十家交易所使用不同的交易机制和费用,允许你将代币 A 交换为代币 B。如果这些是典型的交易所,如纳斯达克,每个交易所将报告自己的数据在 10k 或一些 API,然后其他一些服务,比如 capIQ,会把所有交换数据放在一起,然后收取费用,让你访问他们的 API。也许有时候,他们会举办一次创新竞赛,这样他们就可以在未来收取额外的数据/图表功能。
在 web3 交易所中,我们有这样的数据流:
dex.trades 是 Dune 上的一个表格(由许多社区分析工程师随着时间的推移整理而成),所有的 DEX 交换数据都被聚合在一起,所以你可以很容易地在所有交易所中搜索单个代币的交易量。
声音 | Ripple首席执行官:一些加密货币企业已经采取方法规避政府和监管:据ambcrypto报道,Ripple首席执行官Brad Garlinghouse最近在接受Fox Business采访时表示,我非常同意总统上周在推特上的观点。我们思考这些新技术是至关重要的,就像他们思考任何新技术的监管框架一样。我确实认为一些加密货币企业已经采取了方法,我们如何规避政府,如何规避监管?但我认为,同样明显的是,我们不应该把这件事画成一刀切。任何新技术都可能以各种方式被滥用,Ripple致力于通过伙伴关系和合作,使受监管的机构和银行等金融机构变得更有效率。[2019/7/21]
一名数据分析师通过社区开源查询创建了一个仪表盘,所以现在我们对整个 DEX 行业有了一个公开的概述。即使所有的查询看起来都是由一个人写的,你可以猜测这是在discord上经过大量的争论,才准确地将其拼凑在一起得。
DAO 科学家查看仪表板,并开始在他们自己的查询中分割数据,查看特定的对,比如稳定币。他们会观察用户行为和商业模式,然后开始建立假设。由于科学家可以看到哪个 DEX 在交易量中占据了更大的份额,他们将提出一个新的模型,并提议改变治理参数,以便在链上进行投票和执行。
之后,我们可以随时查看公众查询/仪表板,看看提案如何创造出更具竞争力的产品。
在未来,如果另一个 DEX 出现(或升级到一个新版本),这个过程将重复。有人将创建插入查询来更新这个表。这将反过来反映在所有的仪表板和模型(没有任何人必须回去和手动修复/更改任何东西)。任何其他分析师/科学家都可以以别人已经完成的工作为基础。
动态 | Gemalto与R3合作推出分布式数字身份证管理方法:据Newsbtc消息,荷兰数字安全公司Gemalto与区块链技术公司R3合作推出了分布式数字身份证管理方法,以解决传统身份系统的繁琐问题。[2018/9/19]
由于共享的生态系统,讨论、协作和学习在一个更紧密的反馈循环中发生。我承认这有时会让人难以承受,我认识的分析师基本上都在轮换数据耗尽。然而,只要我们中的一个人继续推动数据向前(例如,某人创建了插入 DEX 查询),那么其他人都会受益。
它并不总是必须是复杂的抽象视图,有时它只是实用功能,如使它容易搜索 ENS 反向解析器或工具的改进,如自动生成大多数 graphQL 映射与一个 CLI 命令!所有这些都可以被每个人重用,并且可以在某些产品前端或您自己的个人交易模型中进行 API 的使用。
虽然这里开启的可能性是惊人的,我确实承认,轮子还没有平稳地运行。与数据工程相比,数据分析师/科学领域的生态系统仍然很不成熟。我认为有以下几个原因:
数据工程是web3多年来的核心焦点,从客户端 RPC API 的改进到基本的 SQL/graphQL 聚合。像 theGraph 和 Dune 这样的产品就是他们在这方面所付出努力的例证。
对于分析师来说,要理解 web3 独特的跨协议关系表是非常困难的。例如,分析人员可以理解如何只分析 Uniswap,但却很难在混合中添加聚合器、其他 DEXs 和不同的代币类型。最重要的是,实现这一切的工具直到去年才真正出现。数据科学家通常习惯于收集原始数据并独自完成所有的工作(建立他们自己的管道)。我认为他们不习惯在开发初期与分析师和工程师进行如此密切和公开的合作。对我个人来说,这花了一段时间。
美国银行获得控制区块链网络访问方法的专利:据coindesk消息,根据美国专利和商标局(USPTO)的文件显示,美国银行于5月22日获得了一项有关控制许可区块链网络访问方法的专利。该专利解释了如何使用安全令牌(基本上是电子密钥,区别于基于区块链的模仿实体证券的资产)来授予某些用户访问包含在特定区块中的信息。根据案文,该系统将是自动化的,意味着网络本身将授予和跟踪访问。[2018/5/23]
除了学习如何协同工作之外,web3 数据社区还在学习如何跨这个新的数据堆栈工作。你不再需要控制基础设施,或者慢慢地从 excel 构建到数据池或数据仓库,只要你的产品上线,你的数据就会到处上线。你的团队基本上是被扔到了数据基础设施的最深处。
以下是一些数据工具汇总:
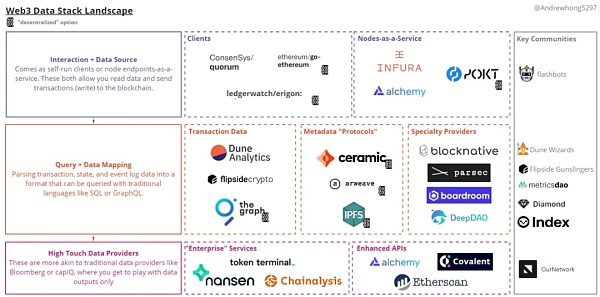
下面我们看看每种类型以及用法:
交互+数据源:这主要用于前端、钱包和较低层次的数据摄取。1
客户端:虽然以太坊的底层实现是相同的,但每个客户端都有不同的额外特性。例如,Erigon 对数据存储/同步进行了大量优化,Quorum 支持隐私链。
节点即服务:你不必选择运行哪个客户端,但使用这些服务将为你节省维护节点和 API 正常运行的麻烦。节点的复杂性取决于你想要捕获多少数据(轻节点→全节点→归档节点)。
查询+数据映射:这一层中的数据要么作为 URI 在合约中引用,要么来自使用合约 ABI 将交易数据从字节映射到表模式。合约 ABI 告诉我们合约中包含哪些函数和事件,否则,我们只能看到部署的字节码(没有这个 ABI,你无法反向工程/解码合约交易)。
交易数据:这些是最常用的,主要用于仪表板和报告。theGraph 和 Flipside API 也在前端中使用。有些表是合约的 1:1 映射,有些表允许模式中额外的转换。
元数据“协议”:这些并不是真正的数据产品,而是用于存储 DIDs 或文件存储的。大多数 NFT 将使用其中的一个或多个数据源,我认为今年我们将开始越来越多地使用这些数据源来增强我们的查询。
专业提供商:其中一些是非常健壮的数据流产品,Blocknative 用于 mempool 数据,Parsec 用于链上交易数据。其他的聚合链上和链外数据,比如 DAO 治理或国库数据。
高维度数据提供商:你不能查询/转换他们的数据,但是他们已经帮你完成了所有繁重的工作。
如果没有强大的、杰出的社区来配合这些工具,web3 就不会出现!我们可以看到每种类型对应的杰出社区:
Flashbots:专注于 MEV 上,提供从保护交易的自定义 RPC 到专业白帽服务的所有事宜。MEV 主要指的是跑问题,当有人支付比你更多的 Gas(但直接给矿商),这样他们就可以抢先执行他们的交易。
Dune 数据精英:专注于为 Dune 的数据生态做贡献的数据分析精英。
Flipside 数据精英:专注于为 Web3 数据升天做贡献的数据分析精英。
MetricsDAO:跨生态工作,处理多个链上的各种数据奖励。
DiamondDAO:专注于 Stellar 的数据科学工作,主要在治理、财政库以及代币管理方面。
IndexCoop:专注于代币等特定领域的分析,以制定加密货币行业最好的指数。
OurNetwork:每周对各类协议以及 ?Web3 的数据覆盖。
注:以上 DAO 的参与联系方式详看原文。
每个社区都做了大量的工作来改善 web3 的生态系统。毫无疑问,拥有社区的产品将以 100 倍的速度增长。这仍然是一个被严重低估的竞争优势,我认为除非人们在这些社区中建立了一些东西,否则他们不会获得这个优势。
不用说,你也应该在这些社区中寻找可以加入你的团队的人。让我们进一步分析重要的web3数据技能和经验,这样你就能真正知道你在搜索什么。如果你想被雇佣,把这看作是你追求的技能和经验!
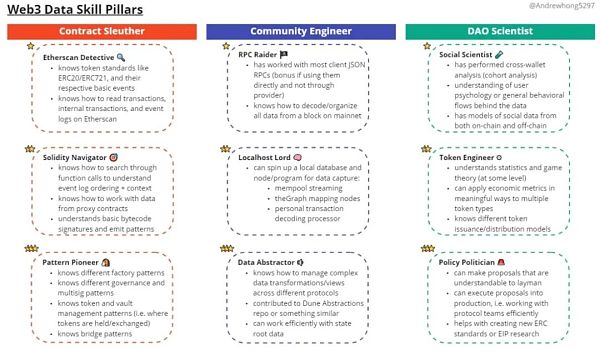
至少,分析师应该是 Etherscan 侦探,知道如何阅读 Dune 仪表盘。这可能需要 1 个月的时间来适应悠闲的学习,如果你真的要疯狂学习,则需要2周的时间。
除此之外,你还需要考虑更多的内容,特别是时间分配和技能转移。
时间方面:在 web3 中,数据分析师大约有 30-40% 的时间将花在与生态系统中的其他分析师和协议保持同步上。请确保你不会气晕他们,否则,这将成为对每个人的长期损害。与更大的数据社区一起学习、贡献和构建是必要的。
可转移性方面:在这个领域,技能和领域都是高度可转移的。如果使用不同的协议,可能会减少上手时间,因为链上数据的表模式都是一样的。
记住,知道如何使用这些工具并不重要,每个分析师或多或少都应该会写 SQL 或创建数据仪表盘。这一切都是关于如何做出贡献并与社区合作。如果你正在面试的人不是任何 web3 数据社区的一员(而且似乎对这一块没有任何兴趣),你可能要问问自己这是否是一个危险信号。
原文链接:
https://ath.mirror.xyz/w2cxg5OP1OEcqvSgsEjSSyKRJhPmam0w-fXGogiG-8g
作者?|?Andrew Hong
译者:GaryMa 吴说区块链
自 2018 年成立以来,福布斯“区块链 50 强”已经记录了全球约 114 家公司对区块链技术的使用情况.
1900/1/1 0:00:00本文由邓建鹏(中央财经大学法学院教授,博士生导师)原创,授权金色财经首发。虚拟货币由于巨大的财富效应,其热潮近年正席卷全球.
1900/1/1 0:00:00第一个进化就是账户自己,元宇宙至少会有四种角色形态,第一种是现实的人。在元宇宙当中他有账户,就像我们今天,比如你有支付宝账户,背后本质上都是一个活生生的人。这个跟现在高速的移动互联网是一样的.
1900/1/1 0:00:00作为投资行业内头部公司的潜藏大佬,很少有人了解 Roelof Botha,这位正在改变硅谷顶级风险投资公司之一的人.
1900/1/1 0:00:00原文标题:《ETHDenver 寻宝:30 个获胜项目你都知道哪些?》30 个获胜项目主要分布在 DeFi、基础设施和元宇宙或游戏类别中.
1900/1/1 0:00:001 月 10 日,NFT 交易市场 LooksRare 发行 Token LOOKS,并向社区空投.
1900/1/1 0:00:00