撰文:Tanya Malhotra
来源:Marktechpost
编译:DeFi 之道

图片来源:由无界版图AI工具生成
随着生成性人工智能在过去几个月的巨大成功,大型语言模型(LLM)正在不断改进。这些模型正在为一些值得注意的经济和社会转型做出贡献。OpenAI 开发的 ChatGPT 是一个自然语言处理模型,允许用户生成有意义的文本。不仅如此,它还可以回答问题,总结长段落,编写代码和电子邮件等。其他语言模型,如 Pathways 语言模型(PaLM)、Chinchilla 等,在模仿人类方面也有很好的表现。
Arbitrum 开发团队 Offchain Labs 将推出针对定序器女巫攻击的防御机制:2月27日消息,Arbitrum 开发团队 Offchain Labs 正在开发题为“添加中继客户端连接随机数”的防御机制,以阻止 MEV 搜索者对定序器进行女巫攻击。该机制要求随机数在不同客户端之间必须是唯一的,中继将按照随机数目标值从高到低的顺序向客户端广播消息,就要有最高随机数目标值的客户端将最快收到消息。如果两个连接的随机数目标值相同,那么随机是哈希值较低的客户端会先收到广播,随后再传播给其他中继。[2023/2/27 12:31:38]
大型语言模型使用强化学习(reinforcement learning,RL)来进行微调。强化学习是一种基于奖励系统的反馈驱动的机器学习方法。代理(agent)通过完成某些任务并观察这些行动的结果来学习在一个环境中的表现。代理在很好地完成一个任务后会得到积极的反馈,而完成地不好则会有相应的惩罚。像 ChatGPT 这样的 LLM 表现出的卓越性能都要归功于强化学习。
Chainlink Labs 聘请 Christian Catalini 为技术顾问:金色财经报道,区块链项目 Chainlink Labs 已聘请 Meta 的 Diem 的联合创始人 Christian Catalini 以及斯坦福密码学家 Dan Boneh 作为技术顾问。
Chainlink 开发“预言机”网络,将现实世界的数据与基于区块链的智能合约连接起来。欧洲电信公司 Deutsche Telekom 是 Chainlink 的主要数据提供商之一。Catalini 和 Boneh 将主要致力于跨链互操作性协议 (CCIP),这是一种用于去中心化跨链消息传递、数据和代币移动的新国际标准。使用 CCIP,用户将能够通过 Chainlink 网络在不同的区块链上移动代币并执行智能合约。(coindesk)[2022/1/28 9:18:24]
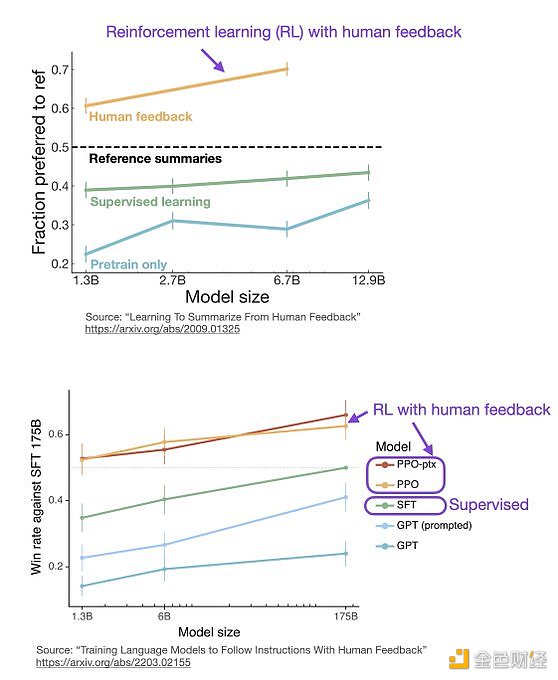
ChatGPT 使用来自人类反馈的强化学习(RLHF),通过最小化偏差对模型进行微调。但为什么不是监督学习(Supervised learning,SL)呢?一个基本的强化学习范式由用于训练模型的标签组成。但是为什么这些标签不能直接用于监督学习方法呢?人工智能和机器学习研究员 Sebastian Raschka 在他的推特上分享了一些原因,即为什么强化学习被用于微调而不是监督学习。
动态 | 汇保互助及其生态社区“Life Chain”上线迅雷链:据天极新闻消息,今日,汇保科技宣布旗下风险互助合约平台—“汇保互助”以及生态社区“Life Chain”上线迅雷链。据了解,2019年2月,汇保互助推出了国内首个风险互助合约社区Life Chain,汇保互助除了以大病、意外作为互助范围,还围绕年轻人在工作生活学习交友的各个场景,全方面缓解社区用户的经济和精神压力。[2019/2/27]
不使用监督学习的第一个原因是,它只预测等级,不会产生连贯的反应;该模型只是学习给与训练集相似的反应打上高分,即使它们是不连贯的。另一方面,RLHF 则被训练来估计产生反应的质量,而不仅仅是排名分数。
币安宣布Binance Chain后 BNB涨幅超25%:昨晚币安宣布决定正式启动专注于区块链资产交易的Binance Chain后,Binance Coin 24小时内涨幅超过了25%,触及11美元的高位。根据coinmarketcap.com的统计,Binance Coin今日以10亿3101万美元市值,超过Zcash,成为市值第24位的加密货币。[2018/3/14]
Sebastian Raschka 分享了使用监督学习将任务重新表述为一个受限的优化问题的想法。损失函数结合了输出文本损失和奖励分数项。这将使生成的响应和排名的质量更高。但这种方法只有在目标正确产生问题-答案对时才能成功。但是累积奖励对于实现用户和 ChatGPT 之间的连贯对话也是必要的,而监督学习无法提供这种奖励。
不选择 SL 的第三个原因是,它使用交叉熵来优化标记级的损失。虽然在文本段落的标记水平上,改变反应中的个别单词可能对整体损失只有很小的影响,但如果一个单词被否定,产生连贯性对话的复杂任务可能会完全改变上下文。因此,仅仅依靠 SL 是不够的,RLHF 对于考虑整个对话的背景和连贯性是必要的。
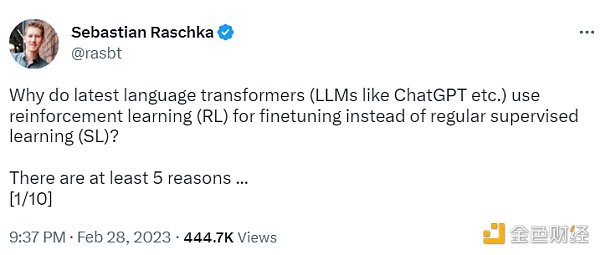
监督学习可以用来训练一个模型,但根据经验发现 RLHF 往往表现得更好。2022 年的一篇论文《从人类反馈中学习总结》显示,RLHF 比 SL 表现得更好。原因是 RLHF 考虑了连贯性对话的累积奖励,而 SL 由于其文本段落级的损失函数而未能很好做到这一点。
像 InstructGPT 和 ChatGPT 这样的 LLMs 同时使用监督学习和强化学习。这两者的结合对于实现最佳性能至关重要。在这些模型中,首先使用 SL 对模型进行微调,然后使用 RL 进一步更新。SL 阶段允许模型学习任务的基本结构和内容,而 RLHF 阶段则完善模型的反应以提高准确性。
DeFi之道
个人专栏
阅读更多
金色财经 善欧巴
金色早8点
Odaily星球日报
欧科云链
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新闻
标签:CHAChainAINHAIComma ChainyuanchaincoinVikingsChainblockchain什么意思中文翻译
撰文:Karen,Foresight News作为 Web3 世界最重要的基础设施和庞大流量入口,加密钱包对于 Web3 大规模采用的重要性不言而喻.
1900/1/1 0:00:00原文作者:Rapolas编译:LlamaC「推荐寄语:在进入行业的第一天起,任何人都绝对无法预测到有天自己可能成为一名链上的医药资本家,而这一切正在悄然发生.
1900/1/1 0:00:00作者:The Block研究主管/img/2023525221341/0.jpg" />2、调整后的稳定币链上交易额减少至5581亿美元.
1900/1/1 0:00:00摘要:人工智能聊天机器人 ChatGPT 一经推出就引发广泛关注,其为社会带来巨大便利的同时,也存在诸多法律风险,主要包括知识产权归属争议,数据来源合法性与用以训练的数据质量问题.
1900/1/1 0:00:00作者:fishman为下一个“Axie”的形态,做一个猜想。在创造更好玩的游戏体验同时,实现为资产赋予价值(而不是价格);通过NFTFi的方式让游戏资产与其他游戏和协议融合与互通;合理利用双代币.
1900/1/1 0:00:00一方面,美国政府对其大力施压,进行了“提醒流动性风险+处罚”的双重施压;另一方面,曾经关系亲密的客户纷纷宣布停止合作。而这一切,都让 Silvergate 濒于破产的边缘.
1900/1/1 0:00:00