摘要
随着AI以超乎想象的速度演化,必将引起对AI利剑的另一“刃”——信任——的担忧。首先是隐私方面:AI时代,人类从数据隐私的角度如何信任AI?也许AI模型的透明度是更为担忧的关键:类似大规模语言模型的涌现能力,对人类来说无异于一个无法看透的科技“黑匣子”,一般用户并不能理解模型是如何运行的、运行结果又是如何获得的——更麻烦的是,作为用户可能并不知道服务商提供的AI模型是否如承诺的那样运行。尤其是在一些敏感数据上应用AI算法和模型,如医疗、金融、互联网应用等,AI模型是否具有偏见(甚至恶意导向)、或者服务商是否按照承诺那样准确无误地运行模型(以及相关参数),成为用户最为关心的问题。零知识证明技术在这方面有着针对性的解决方案,于是零知识机器学习(ZKML)成为最新崛起的发展方向。
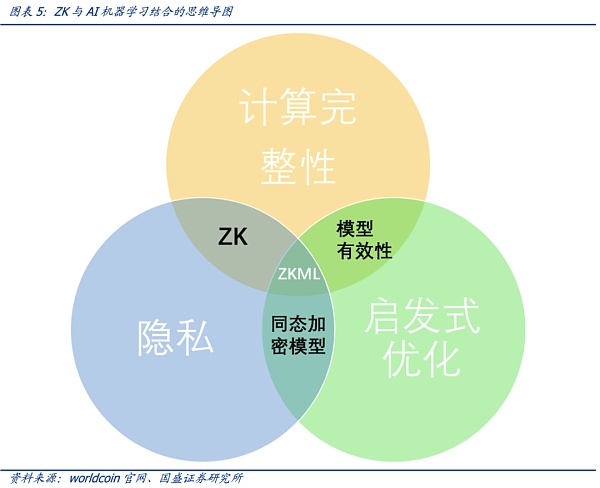
综合考虑到计算的完整性、启发性优化以及隐私,零知识证明和AI的结合下,零知识机器学习(Zero-Knowledge Machine Learning,ZKML)应运而生。在AI生成内容越来越逼近与人类产生的内容的时代,零知识密证明的技术特点可以帮助我们确定特定内容是通过特定模型产生的。对于隐私保护,零知识证明技术特别重要,即可以在不泄露用户数据输入或模型具体细节的情况下完成证明和验证。
零知识证明应用于机器学习的五种方式:计算完整性、模型完整性、验证、分布式训练和身份验证。最近大型语言模型 (LLM) 的快速发展表明这些模型变得越来越智能,这些模型完善了算法与人类的重要接口:语言。通用人工智能 (AGI) 的趋势已经不可阻挡,但就现在的模型训练结果来看,AI可以在数字交互中完美模仿高能力的人类——且在快速的演进中以不可想象的速度达到超越人类的水平,使得人类不得不惊叹这种进化速度、甚至产生被AI迅速替代的忧虑。
社区开发者利用ZKML对Twitter推荐功能进行验证,具有一定启发性。Twitter的“For You”推荐功能利用一种AI推荐算法,将每天发布的大约 5 亿条推文提炼成少数几条热门推文,最终显示在用户主页的时间轴上。2023年3月底,Twitter开源该算法,但因模型细节未公开,用户依然无法验证算法是否准确、完整运行。社区开发者Daniel Kang等利用密码学工具ZK-SNARKs来检查Twitter推荐算法是否正确、完整运行而无需公开算法细节——这正是零知识证明最吸引人之处,即不透露关于对象的任何具体信息(零知识)的前提下证明该信息的可信性。最理想的情况是,Twitter可以使用ZK-SNARKS 来发布其排名模型的证明——证明当该模型应用于特定用户和推文时,它会产生特定的最终输出排名。该证明则是该模型可信的基础:用户可以自行验证模式算法的计算是否按承诺执行——或者交给第三方来进行审计。这一切都是在不公开模型参数权重细节的基础上进行。也就是说,利用官方公布的模型证明,用户对具体的有疑问的推文,利用该证明来验证特定推文是否按照模型承诺那样诚实运行。
Jules Urbach :RNDR 如何成为引领NFT加密艺术浪潮的GPU计算平台:JulesUrbach:RNDR如何成为引领NFT加密艺术浪潮的GPU计算平台3月29日,在以《RNDR渲染网络:引领NFT加密艺术浪潮的GPU计算平台》为主题的AMA中,HuobiGlobalNFT板块项目RNDRNetwork发起人JulesUrbach表示,NFT是实现开放去中心化的虚拟世界的重要基石,而开放去中心化的虚拟世界是RNDR网络自2017年推出以来的愿景。JulesUrbach介绍RNDR将会面向艺术家推出一些新的工具,包括在RNDR网络上铸造带有深度场景图验证的NFT,将ORBX格式的文件变成NFT、生成式艺术(GenerativeArt)等。JulesUrbach还表示,NFT拥有在今天的数字艺术之外的巨大潜力。增强现实、全息显示和实时的沉浸式流媒体将让我们能够在几年后创作出如今只有在科幻小说中才会出现的NFT内容。NFT将可以与物理空间绑定,记录在区块链上的虚拟物体将日益成为人们的日常生活的一部分。[2021/3/29 19:26:18]

1. 核心观点
随着AI以超乎想象的速度演化,必将引起对AI利剑的另一“刃”——信任——的担忧。首先是隐私方面:AI时代,人类从隐私的角度如何信任AI?也许AI模型的透明度是更为担忧的关键:类似大规模语言模型的涌现能力,对人类来说无异于一个无法看透的科技“黑匣子”,一般用户并不能理解模型是如何运行的、运行结果又是如何获得的(本身模型就充满了难以理解或者预测的能力)——更麻烦的是,作为用户可能并不知道服务商提供的AI模型是否如承诺的那样运行。尤其是在一些敏感数据上应用AI算法和模型,如医疗、金融、互联网应用等,AI模型是否具有偏见(甚至恶意导向)、或者服务商是否按照承诺那样准确无误地运行模型(以及相关参数),成为用户最为关心的问题。
零知识证明技术在这方面有着针对性的解决方案,于是零知识机器学习(ZKML)成为最新崛起的发展方向。本文探讨了ZKML技术的特点、潜在应用场景和一些具有启发性的案例,并对ZKML的发展方向及可能的产业影响做了研究阐述。
调查:大部分数字资产持有者担心死后资产如何被处理:2019年10月到2020年6月的调查显示,大部分数字资产持有者担心死后如何处理资产,但是其中很大一部分不会使用遗嘱、信托或者其它工具。89%的受访者不同程度上表示他们很担忧数字资产在他们死后能否传递给家人或者朋友,没有人说完全不担心。(Cointelegraph)[2020/7/8]
2. AI利剑的“另一刃”:如何信任AI?
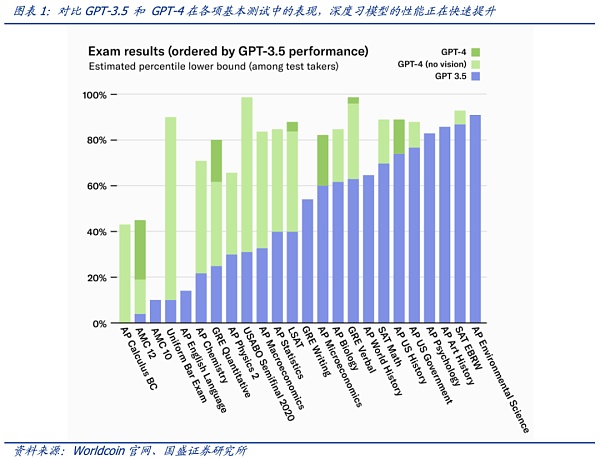
人工智能的能力正在迅速接近人类,并且已经在许多利基领域超越了人类。最近大型语言模型 (LLM) 的快速发展表明这些模型变得越来越智能,这些模型完善了算法与人类的重要接口:语言。通用人工智能 (AGI) 的趋势已经不可阻挡,但就现在的模型训练结果来看,AI可以在数字交互中完美模仿高能力的人类——且在快速的演进中以不可想象的速度达到超越人类的水平。语言模型最近取得了重大进展,以ChatGPT为代表的产品表现惊艳,在大多数常规评估中达到了人类能力的 20% 以上,当比较仅相隔几个月的GPT-3.5 和 GPT-4 时,使得人类不得不惊叹这种进化速度。但另一面则是对AI能力失控的担忧。
首先是隐私方面。AI时代,随着人脸识别等技术的发展,用户在体验AI服务的同时,时刻都在担心数据泄露风险。这给AI的推广和发展带来了一定阻碍——从隐私的角度如何信任AI?
也许AI模型的透明度是更为担忧的关键。类似大规模语言模型的涌现能力,对人类来说无异于一个无法看透的科技“黑匣子”,一般用户并不能理解模型是如何运行的、运行结果又是如何获得的(本身模型就充满了难以理解或者预测的能力)——更麻烦的是,作为用户可能并不知道服务商提供的AI模型是否如承诺的那样运行。尤其是在一些敏感数据上应用AI算法和模型,如医疗、金融、互联网应用等,AI模型是否具有偏见(甚至恶意导向)、或者服务商是否按照承诺那样准确无误地运行模型(以及相关参数),成为用户最为关心的问题。如社交应用平台是否按照“一视同仁”的算法进行相关推荐?来自金融服务商AI算法的推荐是否如承诺的那样准确、完整运行?AI的推荐的医疗服务方案是否有不必要的消费?服务商是否接受对AI模型进行审计?
动态 | 英国信息专员办公室对Facebook发出如何保护个人数据的质询函:据路透社报道,英国信息专员办公室周一表示,其已经向Facebook和其他28家Libra项目背后的公司发送了一份声明,要求他们提供有关如何根据与项目相关的数据保护法处理客户个人数据的详细信息。其同时呼吁,世界各地同行对Facebook提出的天秤币采取更多开放态度。目Facebook没有立即对其进行回复。[2019/8/6]
简单来说,一方面用户并不知道服务商提供的AI模型的真实情况,同时非常担心模型并非“一视同仁”,AI模式被认为加入一些带有偏见或者其他导向的因素,会给用户带来未知的损失或负面影响。
另一方面,AI的自我演化速度似乎越来越难以预测,越来越强大的AI算法模型似乎越来越超出人控制的可能,因此信任问题成为AI这把利剑的另一“刃”。
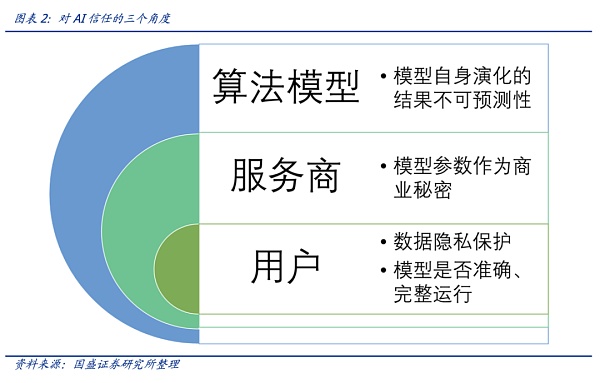
需要从数据隐私、模型透明度、模型可控性等角度建立用户对AI的信任。用户需要担心隐私保护以及算法模型是否如承诺的那样准确、完整运行;然而这并非易事,就模型透明度而言,模型提供商基于商业秘密等角度,对模型的审计和监督方面存有顾虑;另一方面算法模型自身的演化并不易控,这一点不可控性也需要考虑到。
用户数据隐私保护的角度,在我们之前的报告如《Web3.0驱动下的AI和数据要素:开放、安全与隐私》也多有研究,Web3.0的一些应用在这方面极具启发性——即在完整用户数据确权、数据隐私保护的前提下进行AI模型训练。
但目前市场为Chatgpt这类大模型的惊艳表现而折服,还未考虑到模型自身的隐私问题、算法“涌现”特征的演化带来的模型的信任问题(以及不可控性带来的信任),但另一层面,用户对所谓算法模型的准确、完整和诚实运行一直持怀疑态度。因此,AI的信任问题,应该从用户、服务商和模型不可控性三个层面来解决。
韩国政府召开紧急会议 讨论如何遏制加密货币投机:首尔12月13日电 韩国政府周三召集了相关部委的紧急会议,讨论如何在当地投资者日益担忧财务损失的情况下遏制加密货币投机。会议汇集了司法部,财政部,科学部和ICT部,金融服务委员会,韩国通信委员会,公平贸易委员会和国家税务局的高级官员。比特币和以太坊等加密货币近年来迅速普及。韩国是世界上最大的比特币交易所之一,约有100万人拥有最知名的数字货币。[2017/12/13]
3. ZKML:零知识证明与AI结合带来信任
3.1.零知识证明:zk-SNARKS、zk-STARK等技术日趋成熟
零知识证明(Zero Knowledge Proof,ZKP)最早由MIT的Shafi Goldwasser和Silvio Micali在1985年一篇名为《互动式证明系统的知识复杂性》的论文中提出。作者在论文中提到,证明者(prover)有可能在不透露具体数据的情况下让验证者(verifier)相信数据的真实性。公共的函数f(x)和一个函数的输出值y,Alice对Bob说她知道x值,但是Bob不信。为此,Alice使用零知识证明算法,来生成一个证明。Bob验证这个证明,确认Alice是不是真的知道满足函数f的x。
举例来说,利用零知识证明,可以不知道小明考试的成绩,而可以知道其成绩是否满足用户的要求——比如是否及格、是否填空题正确率超过60%等等。在AI领域,结合零知识证明,则可以对AI模型有可靠的信任工具。
零知识证明可以是交互式的,即证明者面对每个验证者都要证明一次数据的真实性;也可以是非交互式的,即证明者创建一份证明,任何使用这份证明的人都可以进行验证。
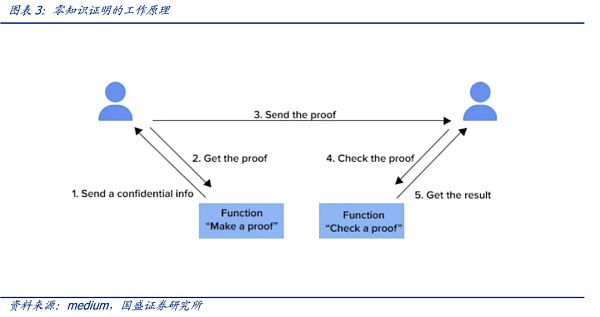
零知识分为证明和验证两部分,一般来说证明是准线性的,即验证是T*log(T)的。
假设验证时间是以交易数量对数的平方,那么10000笔交易一个块的机器验证时间是
VTime = ( )2 ~ (13.2)2 ~ 177 ms;现在将块大小增加一百倍(达到100万tx/块),验证器的新运行时间是VTime = (log2 1000000)2 ~ 202 ~ 400 ms。因此,我们能看到其超强的可拓展性,这就是为什么说,从理论上tps能够达到无限的原因。
比特币如何被盗:5种常见威胁:1、小偷在存储服务中获取您的帐户的密码;2你公开你的私钥;3、黑客冒充比特币收件人;4、你依靠一个不安全的第三方;5、出口局。[2017/12/9]
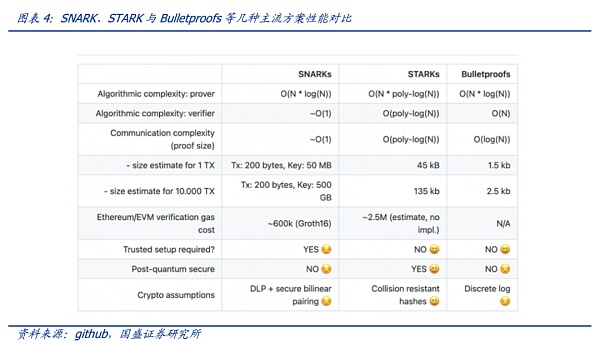
验证是非常快的,而所有的难点就在于生成证明这一部分。只要生成证明的速度跟得上,那么链上验证就很简单。零知识证明目前有多种实现方式,如zk-SNARKS、zk-STARKS、PLONK以及Bulletproofs。每种方式在证明大小、证明者时间以及验证时间上都有自己的优缺点。
零知识证明越复杂、越大,则性能越高,验证所需的时间越短。如下图,STARKs和Bulletproofs无需可信设置,随着交易数据量从1TX激增至10000TX,后者证明的大小增加的更少。Bulletproofs的优点是证明的大小是对数变换(即使f和x很大),有可能将证明存入区块,但其验证的计算复杂度是线性的。可见各类算法都有很多要权衡的关键点,亦有很多待升级的空间,然而在实际运行过程中,生成证明的难度远比想象中的要大,因此现在行业都致力于解决生成证明的问题。
虽然零知识证明技术的发展还不足以匹配类似大语言模型(LLM)的规模,但其技术实现有着启发性的应用场景。特别是在AI双刃剑的发展状况下,零知识证明为AI信任化提供了可靠的解决方案。
3.2.零知识机器学习(ZKML):去信任化的AI
在AI生成内容越来越逼近于人类所产生的内容的时代,零知识密证明的技术特点可以帮助我们确定特定内容是通过将特定模型产生的。对于隐私保护,零知识证明技术特别重要,即可以在不泄露用户数据输入或模型具体细节的情况下完成证明和验证。综合考虑到计算的完整性、启发性优化以及隐私,零知识证明和AI的结合下,零知识机器学习(Zero-Knowledge Machine Learning,ZKML)应运而生。
以下是零知识证明应用于机器学习的五种方式。除计算完整性、模型完整性和用户隐私这些基础功能外,零知识机器学习还能带来分布式训练——这将促进AI与区块链的融合,以及人来在AI丛林里的身份证明(该部分可以详见我们的报告《OpenAI创始人的Web3愿景:Worldcoin打造AI数字通行证》)。

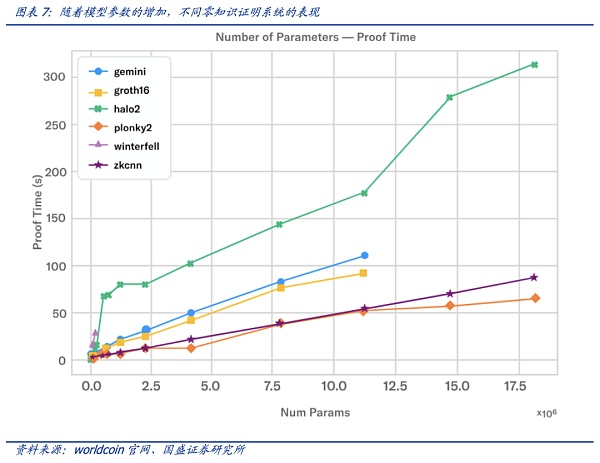
AI大模型对算力的需求是有目共睹的,而此时由将ZK证明穿插到AI应用中来,对硬件算力则带来新的需求。零知识系统的当前技术水平与高性能硬件相结合,依旧无法证明与当前可用的大型语言模型(LLM)一样大的东西,但已经取得了一些进展创建较小模型的证明。根据Modulus Labs团队针对各种不同规模的模型对现有的 ZK 证明系统进行了测试。如plonky2等证明系统,可以在功能强大的 AWS 机器上运行约 50 秒,为大约 1800万参数规模的模型创建证明。
就硬件而言,ZK技术目前的硬件选择包括GPU、FPGA 或 ASIC。需要注意的是零知识证明仍处于早期发展阶段,目前仍然很少有标准化,且算法也在不断更新变化中。每种算法都有其特点,适合于不同的硬件,且随着项目发展需求每种算法都会有一定程度改进,因此很难去具体评估哪种算法最优。
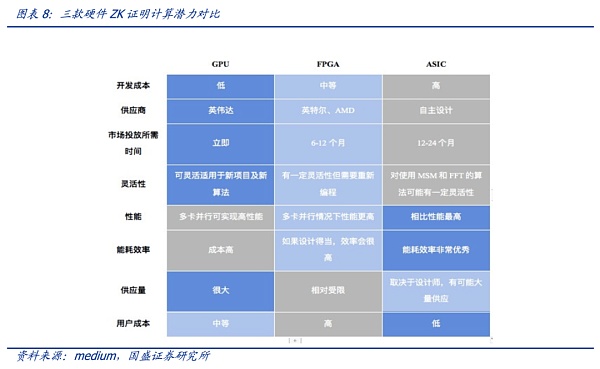
需要注意的是,ZK与AI大模型的结合方面,还未有明确的研究对现有的硬件系统进行评估,因此,未来硬件需求方面还存在较大的变数与潜力。
3.3.启发性案例:验证Twitter推荐排名算法
Twitter的“For You”推荐功能利用一种AI推荐算法,将每天发布的大约 5 亿条推文提炼成少数几条热门推文,最终显示在用户主页的“For You”时间轴上。该推荐从推文、用户和参与数据中提取潜在信息以便能够提供更相关的推荐。2023年3月底,Twitter开源了推荐功能“For You”在时间轴上选择和排名帖子的算法。推荐流程大致如下:
1)从用户与网站的交互中生成用户行为特征,从不同的推荐来源获取最佳推文;
2)使用AI算法模型对每条推文进行排名;
3)应用启发功能和过滤器,例如过滤掉来自用户已阻止的推文内容和已经看过的推文等。
该推荐算法最核心的模块是负责构建和提供 For You 时间线的服务—— Home Mixer。该服务充当连接不同候选源、评分函数、启发式方法和过滤器的算法主干。
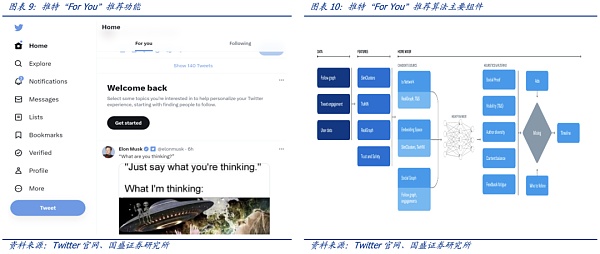
“For You”推荐功能根据大约 1500 个可能相关的候选推荐,预测每个候选推文的相关性并进行评分。推特官网称在此阶段,所有候选推文都受到平等对待。而最核心的排名则是通过一个约 4800万参数的神经网络实现的,该神经网络在推文交互上持续训练以优化。这种排名机制考虑了数千个特征并输出十个左右的标签来为每条推文打分,其中每个标签代表参与的概率,然后根据这些分数对推文进行排名。
虽然这是推特推荐算法迈向透明的重要一步,但用户依然无法验证算法是否准确、完整运行——一个主要原因是用于对推文进行排名的算法模型中具体的权重细节以保护用户隐私的缘由而未公开。因此,算法的透明度依旧存疑。
利用ZKML(零知识机器学习)技术,可以在Twitter 不公开算法模型权重细节的情况下证明是否准确、完整运行(模型及其参数对不同用户是否“一视同仁”),这使得在算法模型隐私保护和透明性之间取得了很好的平衡。
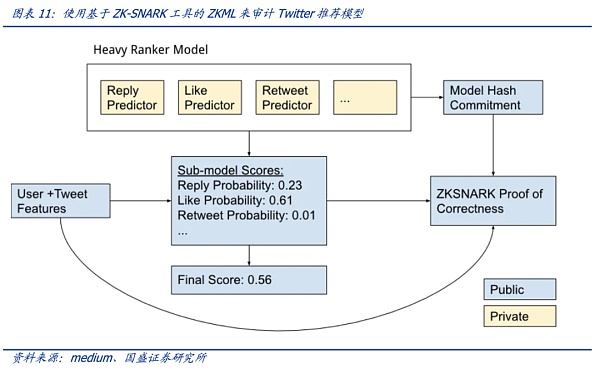
假设用户认为“For You”推荐功能的时间线值得怀疑——认为某些推文的排名应该更高(或低)。如果Twitter 能够上线ZKML证明功能,用户可以利用官方给出的证明来自行检查怀疑的推文与时间轴中的其他推文相比排名如何(计算出的分数对应着排名),如果排名与模型的分数不符,则表示对这些特定推文的算法模型并非诚实运行(而是人为地在一些参数上有变化)。可以这样理解,官方虽然不公布模型的具体细节,但是根据模型给出了一把魔法棒(模型产生的证明),任何推文利用这个魔法棒都能展现相关排名分数——而根据这个魔法棒却无法还原模型隐私细节。因此,官方模型的细节隐私得到保护的情况下获得审计。

站住模型的角度,在保护模型隐私的情况下,利用ZKML技术,依旧可以使模型获得审计和用户的信任。
吉时通信
个人专栏
阅读更多
金色早8点
Odaily星球日报
金色财经
Block unicorn
DAOrayaki
曼昆区块链法律
原文作者:Poopman,加密研究员 原文编译:Leo,BlockBeatscrvUSD 于一个半月前推出,关于其讨论和文章可能很多.
1900/1/1 0:00:00作者:NingNing,独立加密分析师 来源:推特,@0xNing0x 但在这种恶劣的环境下,Web3 游戏仍然有一些令人兴奋的事情在发生,在GameFi的灰烬之下新东西正在萌芽.
1900/1/1 0:00:00由于法律监管不明晰,一些买方机构都表示对加密资产感兴趣,但只是关注。最近,看到一个有意思的调查.
1900/1/1 0:00:00作者:Bankless 编译:Mary Liu这是一个让加密社区心情大起大落的六月.
1900/1/1 0:00:00作者:Leo,区块律动BlockBeatsGMX 可谓是 Arbitrum 上最成功的 DEX 之一,回到之前交互 ARB 的时候,GMX 是 ARB 空投获得者比较重要交互的 DEX.
1900/1/1 0:00:00香港发行自身货币的稳定币,不仅有助于巩固香港的区块链领导地位,也可以推动数码港元的进步,提升交易效能、减少交易成本、改进现行支付系统,进一步强化香港的金融科技实力.
1900/1/1 0:00:00