在数据时代,广告的投放效果评估往往会产生很多的问题。而归因分析要解决的问题就是广告效果的产生,其功劳应该如何合理的分配给哪些渠道。

一、什么是归因分析?
在复杂的数据时代,我们每天都会面临产生产生的大量的数据以及用户复杂的消费行为路径,特别是在互联网广告行业,在广告投放的效果评估上,往往会产生一系列的问题:
哪些营销渠道促成了销售?他们的贡献率分别是多少?而这些贡献的背后,是源自于怎样的用户行为路径而产生的?如何使用归因分析得到的结论,指导我们选择转化率更高的渠道组合?归因分析要解决的问题就是广告效果的产生,其功劳应该如何合理的分配给哪些渠道。
你可能第一反应就是:当然是我点了哪个广告,然后进去商品详情页产生了购买以后,这个功劳就全部归功于这个广告呀!
没有错,这也是当今最流行的分析方法,最简单粗暴的单渠道归因模型——这种方法通常将销售转化归功于消费者第一次或者最后一次接触的渠道。但是显然,这是一个不够严谨和准确的分析方法。
举个例子:
小陈同学在手机上看到了朋友圈广告发布了最新的苹果手机,午休的时候刷抖音看到了有网红在评测最新的苹果手机,下班在地铁上刷朋友圈的时候发现已经有小伙伴收到手机在晒图了,于是喝了一杯江小白壮壮胆回家跟老婆申请经费,最后老婆批准了让他去京东买,有保障。那么请问,朋友圈广告、抖音、好友朋友圈、京东各个渠道对这次成交分别贡献了多少价值?——太难了,笔者也不知道
再举个例子:
下图是某电商用户行为序列图示,各字母代表的含义是D-广告位,Q-商品详情页,D-推荐位,M-购买商品。那么请问,Da、Db、Dc这三种广告位对这次用户购买行为的贡献率分别是多少?这个问题相对简单点,等你看完文章自然就懂了!
我们发现,现实情况往往是很复杂的多渠道投放,在衡量其贡献价值以及做组合渠道投放力度的分配时,只依靠单渠道归因分析得到的结果和指导是不科学的,于是引入了多渠道归因分析的方法。当然,多渠道归因分析也不是万能的,使用怎样的分析模型最终还是取决于业务本身的特性以及考虑投入其中的成本。
USDT活跃地址数创4个月低点:金色财经报道,USDT活跃地址数在过去一小时 (7d MA) 刚刚达到4,601.655个,创4个月低点。[2023/4/11 13:55:34]
二、几种常见的归因模型
1.末次互动模型
也称,最后点击模型——最后一次互动的渠道获得100%的功劳,这是最简单、直接,也是应用最为广泛的归因模型。

优点:首先它是最容易测量的归因模型,在分析计方面不容易发生错误。另外由于大部分追踪的cookie存活期只有30-90天(淘宝广告的计算周期最长只有15天),对于顾客的行为路径、周期比较长的场景,在做归因分析的时候可能就会发生数据的丢失,而对于末次互动模型,这个数据跟踪周期就不是那么特别重要了。
弊端:这种模型的弊端也是比较明显,比如客户是从收藏夹进入商品详情页然后形成了成交的,按照末次归因模型就会把100%的功劳都归功于收藏夹。但是真实的用户行为路径更接近于产生兴趣、信任、购买意向、信息对比等各种环节,这些都是其他渠道的功劳,在这个模型中则无法统计进来,而末次渠道的功劳评估会被大幅高估。
适用于:转化路径少、周期短的业务,或者就是起临门一脚作用的广告,为了吸引客户购买,点击直接落地到商品详情页。
2.末次非直接点击互动模型
上面讲到的末次互动模型的弊端是数据分析的准确性受到了大量的”直接流量”所误导,所以对于末次非直接点击模型,在排除掉直接流量后会得到稍微准确一点的分析结果。
在营销分析里,直接流量通常被定义为手动输入URL的访客流量。然而,现实是市场上的所有分析工具都把没有来源页的流量视为直接流量。比如:文章里没有加跟踪代码的链接、用户直接复制粘贴URL访问等等
从上面的案例中,我们可以想象,用户是从淘宝收藏夹里点了一个商品然后进行了购买,但是实际上他可能是点了淘宝直通车后把这个商品加入到收藏夹的,那么在末次非直接点击互动模型里,我们就可以把这个功劳归功于淘宝直通车。
闪电网络节点数量已达15344个:金色财经报道,据1ML.com数据,目前,支撑网络的节点数量达到15344个,相较30天前数据,环比上涨3.24%;通道数量为36025,相较30天前数据,环比上涨1.2%;闪电网络承载能力目前为1048.38BTC,约合2886.23万美元。[2020/12/27 15:49:31]
适用于:如果你的公司认为,你们业务的直接流量大部分都被来自于被其他渠道吸引的客户,需要排除掉直接流量,那么这种模型会很适合你们。
3.末次渠道互动模型
末次渠道互动模型会将100%的功劳归于客户在转化前,最后一次点击的广告渠道。需要注意这里的”末次互动”是指任何你要测量的转化目标之前的最后一次互动,转化目标可能是销售线索、销售机会建立或者其他你可以自定义的目标。
优点:这种模式的优点是通常跟各渠道的标准一致,如FacebookInsight使用末次Facebook互动模型,谷歌广告分析用的是末次谷歌广告互动模型等等。
弊端:很明显当你在多渠道同时投放的时候,会发生一个客户在第一天点了Facebook的广告,然后在第二天又点击了谷歌广告,最后并发生了转化,那么在末次渠道模型中,Facebook和谷歌都会把这次转化的100%功劳分别归到自己的渠道上。这就导致各个部门的数据都看起来挺好的,各个渠道都高估了自己影响力,而实际效果则可能是折半,如果单独使用这些归因模型并且把他们整合到一个报告中,你可能会得到”翻倍甚至三倍”的转化数据。
适用于:单一渠道,或者已知某个渠道的价值特别大。
4.首次互动模型
首次互动的渠道获得100%的功劳。
如果,末次互动是认为,不管你之前有多少次互动,没有最后一次就没有成交。那么首次互动就是认为,没有我第一次的互动,你们剩下的渠道连互动都不会产生。
换句话说,首次互动模型更加强调的是驱动用户认知的、位于转化漏斗最顶端的渠道。
优点:是一种容易实施的单触点模型弊端:受限于数据跟踪周期,对于用户路径长、周期长的用户行为可能无法采集真正的首次互动。适用于:这种模型适用于没什么品牌知名度的公司,关注能给他们带来客户的最初的渠道,对于扩展市场很有帮助的渠道。
闪电网络节点数量已达15164个:金色财经报道,据1ML.com数据,目前,支撑网络的节点数量达到15164个,相较30天前数据,环比上涨3.04%;通道数量为35988,相较30天前数据,环比上涨1.1%;闪电网络承载能力目前为1061.27BTC,约合2460.59万美元。[2020/12/19 15:48:30]
5.线性归因模型
对于路径上所有的渠道,平等地分配他们的贡献权重。
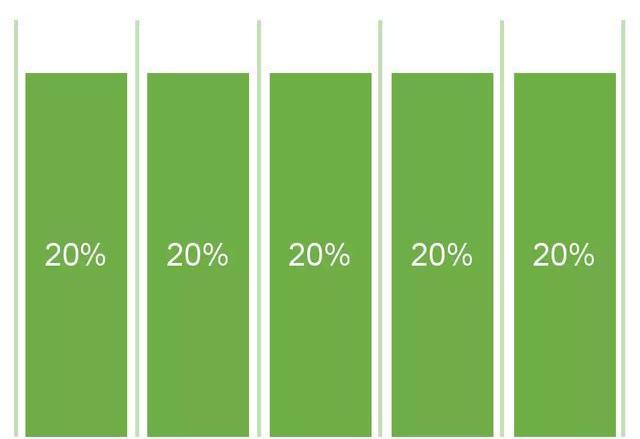
线性归因是多触点归因模型中的一种,也是最简单的一种,他将功劳平均分配给用户路径中的每一个触点。
优点:他是一个多触点归因模型,可以将功劳划分给转化漏斗中每个不同阶段的营销渠道。另外,他的计算方法比较简单,计算过程中的价值系数调整也比较方便。
弊端:很明显,线性平均划分的方法不适用于某些渠道价值特别突出的业务。比如,一个客户在线下某处看到了你的广告,然后回家再用百度搜索,连续三天都通过百度进入了官网,并在第四天成交。那么按照线性归因模型,百度会分配到75%的权重,而线下某处的广告得到了25%的权重,这很显然并没有给到线下广告足够的权重。
适用于:根据线性归因模型的特点,他更适用于企业期望在整个销售周期内保持与客户的联系,并维持品牌认知度的公司。在这种情况下,各个渠道在客户的考虑过程中,都起到相同的促进作用。
6.时间衰减归因模型
对于路径上的渠道,距离转化的时间越短的渠道,可以获得越多的功劳权重。
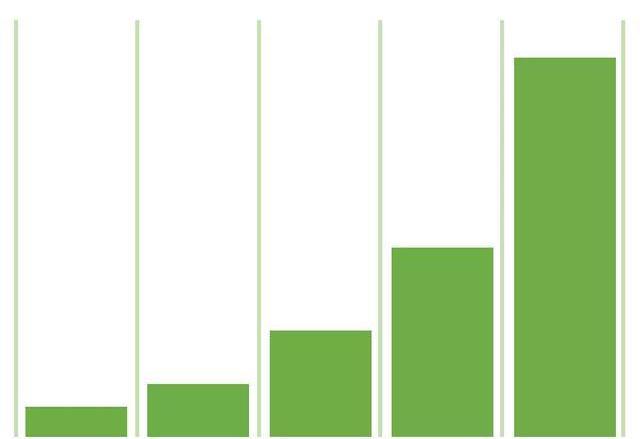
时间衰减归因模型基于一种假设,他认为触点越接近转化,对转化的影响力就越大。这种模型基于一个指数衰减的概念,一般默认周期是7天。也就是说,以转化当天相比,转化前7天的渠道,能分配50%权重,前14天的渠道分25%的权重,以此类推……
优点:相比线性归因模型的平均分权重的方式,时间衰减模型让不同渠道得到了不同的权重分配,当然前提是基于“触点离转化越近,对转化影响力就越大”的前提是准确的情况下,这种模型是相对较合理的。
动态 | 迪拜酋长启动4个创新实验室,将重点关注区块链等领域:阿联酋副总统、总理、迪拜酋长Sheikh Mohammed bin Rashid Al Maktoum宣布启动4个创新实验室,重点关注航空、能源、区块链和创业领域。Sheikh Mohamme表示,“我们的最终目标是使这些实验室成为启动面向未来创新的中心,最终提升我们的商业和服务部门。”这些实验室将支持阿联酋的百年计划2071,并将为建立一个全球中心奠定基础,以为该国未来创新做准备。(Trade Arabia)[2019/10/29]
弊端:这种假设的问题就是,在漏洞顶部的营销渠道永远不会得到一个公平的分数,因为它们总是距离转化最远的那个。
适用于:客户决策周期短、销售周期短的情况。比如,做短期的促销,就打了两天的广告,那么这两天的广告理应获得较高的权重。
7.基于位置的归因模型
基于位置的归因模型,也叫U型归因模型,它其实是混合使用了首次互动归因和末次互动归因的结果。
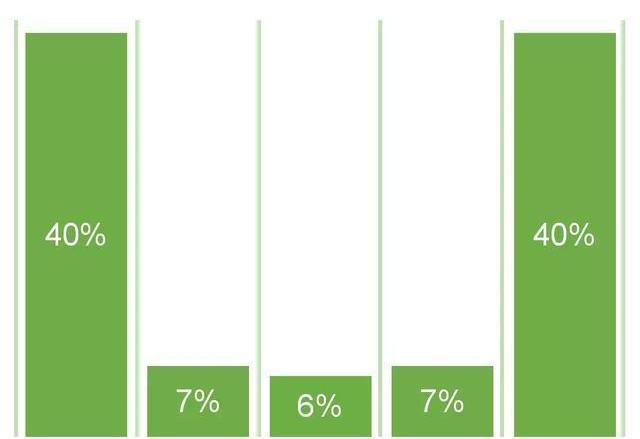
U型归因模型也是一种多触点归因模型,实质上是一种重视最初带来线索和最终促成成交渠道的模型,一般它会给首次和末次互动渠道各分配40%的权重,给中间的渠道分配20%的权重,也可以根据实际情况来调整这里的比例。
U型归因模型非常适合那些十分重视线索来源和促成销售渠道的公司。该模型的缺点则是它不会考虑线索转化之后的触点的营销效果,而这也使得它成为销售线索报告或者只有销售线索阶段目标的营销组织的理想归因模型。
归因分析模型的计算原理演绎:
以下,我们通过神策数据提供的归因模式,做一次计算原理的演绎:
下图是通过神策分析所得到某电商用户行为序列图示。在图示中,各字母代表的含义是D-广告位、Q-商品详情页、D-推荐位、M-购买商品。目标转化事件是“购买商品”,为了更好地“配对”,运营人员将M1与Q1设置了属性关联,同样将M2与Q2进行关联。
该场景中,发生了两次购买行为,神策分析进行归因时会进行两轮计算,产生计算结果。
动态 | 今日Dapp新增4个:据DappReview数据显示,今日Dapp新增4个。EOS Dapp活跃用户70365人,交易额3959万元(+27%);Tron Dapp活跃用户39746人,交易额8111万元(+76%);ETH Dapp活跃用户15586人,交易额4142万元(+78%)。过去24小时Dapp交易额:EOS最高的为“鲸交所”(交易额2774万元);Tron最高的为“WINk”(交易额6592万元);ETH最高的为“MakerDAO”(交易额1358万元)。[2019/10/8]
第一轮计算:
第一步,从M1开始向前遍历寻找Q1以及离Q1最近发生的广告浏览。
如图所示,不难得到结果M1=。
第二步,我们带入分析模型中,进行功劳的分配。运营人员选择“位置归因”的分析模型,根据“位置归因”的计算逻辑,第一个“待归因事件”和最后一个“待归因事件”各占40%,中间平分20%。
第一轮我们得到结果:Dc=0.4;Dc=0.2;Da=0.4
第二轮计算:
从M2开始向前遍历寻找Q2以及离Q2最近发生的广告浏览。
这里值得强调的是,即使第一轮中计算过该广告,在本轮计算时依然会参与到计算中,因为经常会出现一个广告位同时推荐多个商品的情况。
我们不难得到结论,M2=。基于这个结论,我们通过“位置归因”得到结果:Dc=0.5;Db=0.5。
经过两轮计算,我们得出结论:Dc=1.1;Da=0.4;Db=0.5,则广告位c的贡献最大、广告位b贡献次之,广告位a的贡献最小。
8.马尔科夫链
马尔科夫链模型来自于数学家AndrewMarkov所定义的一种特殊的有序列,马尔科夫链(MarkovChain),描述了一种状态序列,其每个状态值取决于前面有限个状态,马尔科夫链是具有马尔科夫性质的随机变量的一个数列。
马尔科夫链思时间、状态都是离散的马尔科夫过程,是将来发生的事情,和过去的经理没有任何关系。通俗的讲:今天的事情只取决于昨天,而明天的事情只取决于今天。
谷歌的PageRank,就是利用了马尔科夫模型。假设有A,B,C三个网页,A链向B,B链上C。那么C分到的PR权重只由B决定,和A没有任何关系。如果互联网上所有的网页不断地重复计算PR,很容易可以想到这个PR值最后会收敛,并且区域一个稳定的值,这也就是为什么它会被谷歌用来确定网页等级。
回到归因模型上,马尔科夫链模型实质就是:访客下一次访问某个渠道的概率,取决于这次访问的渠道。
归因模型的选择,很大程度上决定转化率计算结果,像前面讲的首次互动、末次互动等模型,实际上需要人工来分配规则的算法,显然它并不是一种“智能化”的模型选择。而且因为各个推广渠道的属性和目的不同,我们也无法脱离用户整个的转化路径来单独进行计算。因此,马尔科夫链归因模型实质上是一种以数据驱动的(Data-Driven)、更准确的归因算法。
马尔科夫链归因模型适用于渠道多、数量大、有建模分析能力的公司。
那么具体马尔科夫链怎么玩?
如果将各推广渠道视为系统状态,推广渠道之间的转化视为系统状态之间的转化,可以用马尔科夫链表示用户转化路径。
马尔科夫链表示系统在t+1时间的状态只与系统在t时间的状态有关系,与系统在t-1,t-2,…,t0时间的状态无关,平稳马尔科夫链的转化矩阵可以用最大似然估计,也就是统计各状态之间的转化概率计算得到。用马尔科夫链图定义渠道推广归因模型:
状态集合,定义为banner,text,keyword,link,video,mobile,unknown7种推广类型加上start,,conversion3种系统状态。
稳定状态下的转化矩阵,通过某公司web网站20天的原始click数据计算的得到如下状态转化矩阵。
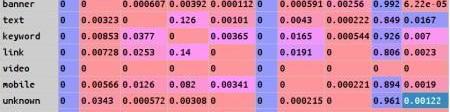
利用该转化矩阵来构造有向图,通过计算从节点start到节点conversion的所有非重复路径的累乘权重系数之和来计算移除效应系数4、通过移除效应系数,计算各个状态的转化贡献值
什么是移除效应?
渠道的移除效应定义为:移除该状态之后,在start状态开始到conversion状态之间所有路径上概率之和的变化值。通过计算各个渠道的移除效应系数,根据移除效应系数在总的系数之和之中的比例得到渠道贡献值。移除效应实际上反映的是移除该渠道之后系统整体转化率的下降程度。
我们可以把上面的案例简化一下,尝试具体计算下移除效应和各渠道的转化贡献值:
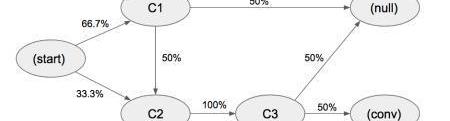
假设简化后的状态集是{C1,C2,C3},各路径上代表状态间转化的概率。
在以上系统中,总体的转化率==33.3%。

当我们尝试移除节点C1。
移除节点C1后,整体转化率=0.333*0.1*0.5=16.7%,所以C1节点的移除效应系数=1-0.167/0.333=0.5同理可计算节点C2和C3的移除效应分别是1和1通过移除效应系数计算得到转化贡献值:C1:0.5/(0.5+1+1)=0.2C2:1/(0.5+1+1)=0.4C3:1/(0.5+1+1)=0.4
三、如何选择归因模型
从上面这么多种归因模型来看,我们大概可以把他们分成2类:
基于规则的:预先为渠道设置了固定的权重值,他的好处是计算简单、数据容易合并、渠道之间互不影响,当然你也可以根据实际需要去调整他们的权重配比。
基于算法的:每个渠道的权重值不一样,会根据算法和时间,不同渠道的权重值会发生变化。
在选择用何种归因模型之前,我们应该先想清楚业务模式!
如果是新品牌、新产品推广,企业应该给予能给我们带来更多新用户的渠道足够的权重,那么我们应该选择首次互动模型;如果是投放了单一的竞价渠道,那么我们应该选取末次互动归因模型或者渠道互动归因模型;如果公司很在乎线索来源和促成销售渠道,那么我们应该选择U型归因模型;如果公司的渠道多、数据量大,并且由永久用户标识,基于算法的归因模型能够为营销分析提供巨大的帮助;……总的来说,没有完美的归因模型。任何模型都存在他的局限性和不足,如何有效地结合客观数据与主观推测,是用好归因模型的重要能力前提。
四、还有哪些有趣的归因模型?
这里抛出一个有趣的问题,大家可以通过思考他背后的分析逻辑,尝试一下如何应用到归因模型中:
小陈和小卢同学准备吃午餐,小陈带了3块蛋糕,小卢带了5块蛋糕。这时,有一个路人路过,路人饿了,于是他们约路人一起吃午饭,路人接受了邀约。小陈、小卢和路人3个人把8块蛋糕全部吃完了,吃完饭后,路人感谢他们的午餐,于是给了他们8个金币,然后离去。小陈和小卢为这8个金币的分配展开了争执。小卢说:我带了5块蛋糕,理应我得5个金币,你得3个金币。小陈不同意:既然我们一起吃这8块蛋糕,理应平分这8个金币。为此他们找到了公正的夏普里。夏普里说:公正的分发是,小陈你应当得到1个金币,你的好朋友小卢应该得到7个金币。经过夏普里的解释,小陈和小卢认为很有道理,愉快地接受了这种分金币的方案。请问,夏普里是怎样分析得到1:7这样的分配的呢?
本文由@WINTER原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
时间转向2018年,打着「区块链+视频」概念的火牛视频快速蹿红,该平台依靠拉新奖励与高额分红吸引了大批用户。有媒体报道称,当年的火牛视频平台总计充值用户大概在290万左右,总充值金额6亿以上.
1900/1/1 0:00:00好看的皮囊经不起扫黄打非,有趣的灵魂又涉嫌账号违规,大家好,我是异说俱乐部成员吉吉国王。 星际战甲要更新了? 话说今天吉吉国王刚登录wegame的时候看到一条消息吓了我一跳,给各位小伙伴们看一下.
1900/1/1 0:00:00俗话说“有钱能使鬼推磨”,在这个现实的社会里,钱财可以解决许多现实问题,有了钱,我们可以衣食无忧;有了钱,我们可以行走各地,游山玩水,赏花踏青;有了钱,我们可以买自己喜欢的物品……然而.
1900/1/1 0:00:00新的一周又开始了,下周又会有哪些好玩的新游戏等着我们呢?一起来看看吧。划重点:宝可梦新作发布会宣布6月24日将会公布“大计划”在本周举行的“宝可梦新作发布会”上,宝可梦公司的CEO石原恒不仅公布.
1900/1/1 0:00:00微信订阅号“乱序阅读”来了,你还用的习惯吗? 微信订阅号推文时间顺序打乱,貌似现在已经全量覆盖。安卓和IOS用户应该都体验到了,看订阅号推文时不再完全按推送时间顺序进行展现.
1900/1/1 0:00:00不知不觉进入币圈已经半年了,在这段时间里、接触最多的是柚子。记得当时没人教我,我就瞎琢磨,有时候看资料看到深夜.
1900/1/1 0:00:00