一种针对肺结节的无创多元分析法诊断肺癌
摘要
为了解决常规低剂量CT在肺癌诊断中的假阳性率高的问题,此次研究采用基于血液样本的无创性检测来协助临床医生进行肺结节诊断的决策的功效。在这项前瞻性观察性研究中,通过LDCT筛选高危的PNs的患者进行了基于二代测序技术的游离DNA突变分析,基于NGS的cfDNA甲基化分析以及基于血液的蛋白质癌症生物标志物检测,然后进行手术切除,并对组织切片进行病理检查和分类。以病理学分类为金标准,使用统计和机器学习方法基于98位患者的发现队列选择与组织恶性分类相关的分子标记,并构建预测组织恶性肿瘤的综合多分析预测模型。基于各个测试平台的预测模型表现出不同的性能水平,而它们的最终集成模型AUC为0.85。该模型的性能在29位患者的独立验证队列上得到了进一步证实,其AUC值为0.86,总体敏感性为80%,特异性为85.7%。
引文
低剂量计算机断层扫描(LDCT)通常用于筛查高危患者的肺癌(LC)。当使用来自基于美国的国家肺筛查试验的阳性筛查的原始定义时,LDCT性能受到大量阳性调用(27%)的影响,其中96%已被确定为假阳性。随后的Nelson试验使用基本上不同的阳性筛查结果定义来将假阳性的比例降低到60%,但这导致LC检测的敏感度下降了10倍,阳性率为2.7%。由于小的恶性结节的放射学特征不明确,在CT扫描中区分小的恶性结节与良性结节尤其具有挑战性。因为在中国人群中结核球的患病率相对较高,这使问题变得更加复杂,所以这个问题在作者所在的医院尤为突出。面对类似的困境,许多临床上用于广泛评估癌症风险的生物标记物缺乏所需的特异性。例如,基于血清蛋白的癌症生物标志物,如癌症抗原125(CA125)、癌胚抗原(CEA)、前列腺特异性抗原(PSA)和癌症抗原19-9(CA199)通常用于监测肺癌患者。但是这些蛋白也在非癌症患者的血清中被发现,这限制了它们在早期肺癌诊断中的临床应用。因此,人们一直在寻找特异性更高的生物标志物来补充现有的临床实践。循环肿瘤DNA(CtDNA)是基于无细胞DNA(CfDNA)研究的主要肿瘤学研究热点之一,它为肿瘤特异性基因组改变的无创性研究提供了一个很有前途的平台。ctDNA研究通常只需要从患者身上提取液体,如血液、胸水、脑脊液等,与传统的手术活检方法相比,对实体肿瘤微环境的影响最小,从而避免了应激诱导的肿瘤细胞增殖。下一代测序技术(NGS)的应用,加上先进的计算方法,使得基于ctDNA的肿瘤突变图谱在广泛的癌症类型中得到了极大的应用。有时参考肿瘤组织测序图谱以指导治疗,这些方法已经成功地应用于确诊的癌症患者。与此同时,尽管有许多备受瞩目的研究论文,基于血液的突变图谱在癌症筛查和早期检测中的应用仍处于初级阶段。这可能是因为当肿瘤很小时,这些突变靶点的等位基因频率非常低,因此它们对现有技术的可靠检测构成了挑战。特别是关于肺癌,Phallen等人,比较早期肺癌和健康人的cfDNA突变谱,报道它们可能是潜在的非侵入性检测生物标志物。然而,用于区分良恶性肺结节的突变生物标志物的研究报道甚少。DNA序列的全局低甲基化和CpG岛(CpG岛)的局部高甲基化在肿瘤发生的早期阶段被广泛观察到,这使得DNA甲基化图谱成为癌症早期检测的一种有吸引力的方法。已经有几项研究报道了基于血液的肺癌筛查和诊断。Ooki等人,设计了用于早期肺癌检测的cfDNA甲基化小组,但仍以健康对照为基础。Hulber等人报道称,6个基因启动子区域的甲基化特征对早期肺癌具有较高的诊断准确率。据报道,该技术对中国小结节患者早期非小细胞肺癌的检测具有很高的敏感性和特异性。梁等人报道的一项临床研究。研究表明,9种特定的甲基化标记物在区分肺癌和良性肺结节(PN)方面是有效的。这种概念验证工作在应用于临床之前通常需要进一步改进,因为该测试的性能与更传统和更方便的LDCT相当。使用单一技术平台进行分析的一个突出问题是成像、蛋白质生物标记物、DNA突变或DNA甲基化,这与选择用于构建预测模型的生物标记物有关。考虑到肿瘤生物学的复杂性,单一的测试平台很容易对预测模型引入系统性的研究偏差,因为观察数据只反映了患者/样本的一个方面。此外,临床研究经常在有限的队列规模下面临现实的挑战,再加上对潜在预测标记物的巨大搜索空间,结果模型在不同的平台和研究中表现出巨大的差异并不令人惊讶。自然,对多组学数据的综合分析可以提供对患者的更全面的看法,减少系统偏差和方差,从而促进更准确的临床决策。少量研究已经表明结合多组学特征可以提高癌症筛查的性能。例如,Cohen等人的CancerSeek小组发现基于DNA点突变和蛋白质的肿瘤标志物在区分可切除肺癌和正常标本方面的敏感性和特异性分别达到59%和99%,Silverstri等人的PANOPTIC分类器发现根据蛋白癌生物标志物和患者的临床特征,可以区分肺结节的良、恶性,敏感性为97%,特异性为44%。我们的研究旨在从两个方面提升上述技术水平。首先,我们关注的是具有挑战性的临床应用,即区分恶性病变和良性病变,而不是肿瘤组织和正常标本。病变是病理改变的组织,无论其恶性程度如何,与正常标本相比,可能具有更高水平的分子特征,因此需要更微妙和更难区分的恶性和良性病变。其次,我们通过整合包括临床特征、蛋白质生物标志物、cfDNA突变和cfDNA甲基化在内的多种多组学平台来评估性能改善的水平,以减少系统偏差和方差,从而提高肺PNs的诊断效率。在这个概念验证阶段,我们的目标不是取代广泛采用的LDCT及其随后的临床医生评审过程,而是提供额外的评估指标来帮助临床医生做出决策。考虑到LDCT对假阳性率的限制,我们的目标是提高我们测试的特异性,这样,当我们的测试结果与LDCT成像一起考虑时,临床医生将变得更有信心,将阴性病例排除在随后不必要的治疗之外。
社区农场主题链游Cosmocadia已上线Sui主网:5月25日消息,社区农场主题链游Cosmocadia已上线Sui主网,并成为Sui开发公司Mysten Labs的官方合作伙伴。[2023/5/25 10:38:54]
结果与讨论
我们的研究遵循典型的“监督学习”范式,包括两个连续的阶段。在发现阶段,使用统计学和机器学习的方法对发现队列中样本的各种临床和分子特征进行评估,以确定对PN恶性程度有预测意义的潜在标记物。然后构建了预测模型,并对模型进行了参数优化,对模型进行了检验。在验证阶段,进一步以独立的验证队列为基准对优化后的预测模型进行基准测试,以评估模型对未知样本的泛化能力。读者应该注意到,由于篇幅的限制,以及以临床实践人员为目标受众,我们手稿的其余部分稍微倾向于分析结果对其作出解释,以及它们在临床设置中的真实世界含义,而不是数据处理和数据分析的计算方法的算法细节。
研究对象和样本特征
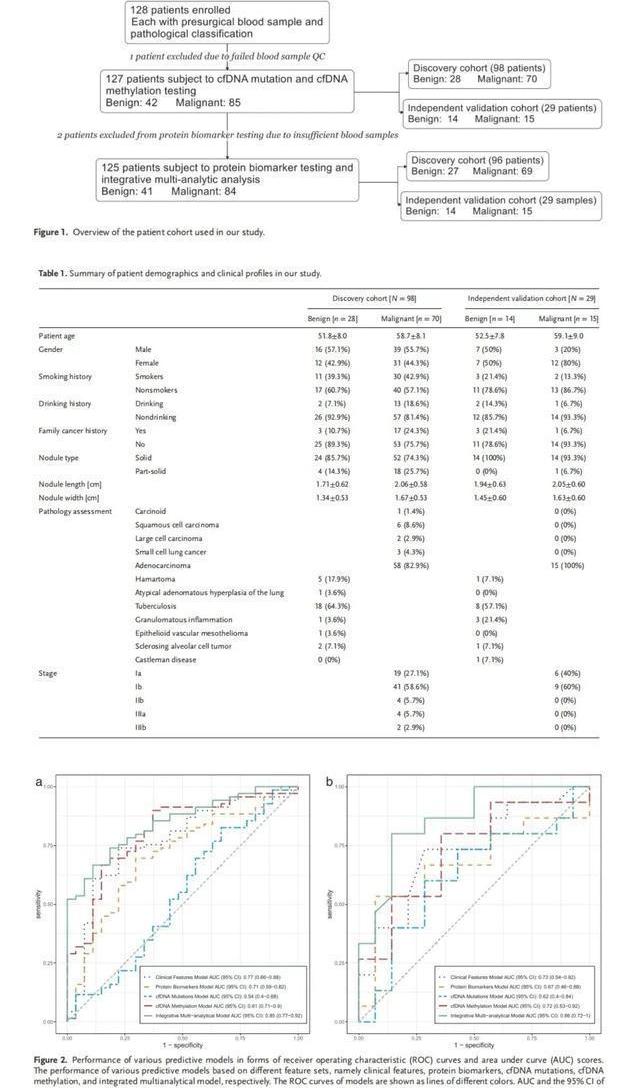
这项研究包括2019年2月17日至2019年12月10日期间CT筛查出直径<3cm的肺结节呈阳性并随后接受手术切除的患者的组织和血浆样本。所有登记的患者都被要求没有既往癌症病史。本研究在手术前抽取了足够数量的血液样本,因此需要一个前瞻性的观察性临床设置,尽管数据分析是在不影响最初临床决定的情况下进行的。在发现阶段,患者在没有选择的情况下被招募和测试,以保证队列中真实的阳性(恶性)率。在验证阶段,鼓励LDCT检测置信度低(即更可能为阴性/良性)的高危患者(基于临床因素)参加研究,以满足基于功率分析的队列大小标准。PN标本的病理评估以手术切除的组织切片为基础,符合2015年WHO肺癌组织分类标准,所有标本的采集均经陆军军医大学第二附属医院伦理委员会批准(项目ID:2019-009-01),所有参与者均提供书面知情同意书。
最初收集了99份血浆样本,并登记在发现队列中。其中1个样本因质控不合格而被排除,剩下98个样本需要进行多分析检测,其中良性PNS患者28个,恶性PNS患者70个。两名患者(一名良性,一名恶性)没有进行蛋白质生物标志物检测,因此被排除在蛋白质生物标志物发现和综合多分析模型研究之外。在发现研究之后,一组单独的29个样本(14个良性样本和15个恶性样本)进入了独立的验证队列(图1)。在分析接近尾声时,回顾性登记的样本还包括57个组织样本,用于根据选定的甲基化特征位点,评估同一个体的配对组织和血浆之间DNA甲基化特征的一致性。类似地,对55个组织样本进行了DNA突变测序,以评估与其配对血浆样本的一致性。
临床特征与PN恶性程度的相关性及其预测能力
收集患者年龄、性别、吸烟史、饮酒史、肿瘤家族史、结节长度、结节宽度、CT上结节密度等临床资料。进一步推导了根瘤长度×根瘤宽度和(根瘤长度+根瘤宽度)/2两种形式的结瘤大小计算公式。表1总结了患者队列的分布及其临床特征。
四个结节大小测量结果显示,在发现队列中有足够的统计学意义,其AUC略低于患者年龄,从0.66到0.72不等。然而,当我们使用患者年龄和结节大小特征的不同组合来预测PN恶性肿瘤时,所有模型的表现都比单变量患者年龄模型差。这表明,尽管结节大小可能在群体水平上作为恶性结节和良性结节之间的区别标志,但它本身在个体样本水平上缺乏预测能力。这可能表明,不是结节的大小,而是结节的细胞组成和分子特征与其恶性程度有更大的关系,因此除了计算机断层成像分析之外,还需要进行全面的分子研究
多种蛋白质生物标志物综合分析用于PN恶性程度评估
在新桥医院测定了临床癌症筛查中最常用和最方便获得的八种蛋白质癌症生物标志物,即癌症抗原125(CA125)、癌症抗原15-3(CA15-3)、癌胚抗原(CEA)、细胞角蛋白-19片段(CYFRA21-1)、神经元特异性烯醇化酶(NSE)、促胃泌素释放肽前体(PROGRP)、鳞状细胞癌抗原(SCC)和血清铁蛋白(SF)。基于化学发光免疫分析(CLIA)平台,并遵循制造商的标准操作程序(标准操作程序),所使用的试剂盒包括用于CA125的CA125二型试剂盒(雅培公司),CA15-3试剂盒(雅培有限公司KG)用于CA15-3,癌胚抗原试剂盒(雅培爱尔兰诊断部)用于癌胚抗原,ARCHITECTCYFRA211试剂盒(雅培有限公司KG)用于CYFRA21-1,ARCHITECTProGRP试剂盒(雅培有限公司KG)用于ProGRP,ARCHITECTSCC试剂盒(雅培有限公司KG)用于SCC,铁蛋白试剂盒(雅培爱尔兰诊断部)用于SF。最后,神经元特异性烯醇化酶用电化学发光检测试剂盒(ECLIA,罗氏诊断有限公司)按照标准操作程序进行测定。
Bitfinex首席技术官:闪电网络非常适合缓解比特币网络的拥堵问题:金色财经报道,Bitfinex首席技术官兼非官方发言人Paolo Ardoino表示:“闪电网络非常适合缓解比特币网络的拥堵问题。在 Bitfinex,我们在过去 30 天内看到了 11,000 笔交易,我预计这一数字只会增长。我们需要更多的交易所和更多的交易所用户来推动闪电网络,以便从更快的速度和更低的成本中获益。Blockstream 的 Liquid 网络也是一个很好的辅助层,可以在BTC主网拥塞的情况下提供帮助。”[2023/5/10 14:53:57]
基于对发现队列的单变量分析(表S3a,支持信息),CEA、CYFRA21-1和SCC显示出统计显著性(表S4,支持信息),预测AUC分别为0.72、0.68和0.67。使用这三个标记,构建了基于支持向量机(SVM)的多变量预测模型,并在自举AUC=0.71的发现队列中进行了测试(图2a)。
虽然多变量模型的AUC略低于单变量CEA,但我们之前的经验实验表明,由于自举过程中的子采样,这是一个可接受且可忽略的性能波动,这有时实际上表明模型可能已经达到了相对稳健的局部优化。尽管如此,蛋白质癌症生物标志物,当单独或联合用于预测时,在同一个发现队列中始终表现不如早期选择的临床特征(患者年龄)。虽然这看起来有些令人惊讶,但鉴于众所周知的蛋白质癌症生物标志物检测缺乏特异性,这仍然是可以理解的。
基因突变谱在PN恶性肿瘤分析中的局限性
cfDNA突变测试是在基因科技生物技术有限公司进行的,使用了一个独特的基于分子标识符(UMI)和基于捕获的29基因NGS小组(实验组),通过内部生物信息学管道调用体细胞突变(实验组)。29基因组的设计是基于与癌症起源和发展最相关的基因的治疗,以及基于公共数据库的突变流行率,包括癌症基因组图谱(TCGA)和癌症体细胞突变目录(COSMIC)。根据已建立和验证的标准进行必要的质量控制检查和过滤后,发现队列中每个cfDNA样本中检测到的体细胞突变数量从2到47不等,中位数为13,平均值为14.3(表S5,支持信息)。
对个体突变的进一步审查表明,它们在发现队列中的患病率很低。这可能是由于癌症起源和演变的复杂性,以及队列中相当大比例的非癌样本。这给我们的标记选择工作带来了巨大的挑战,因为通过对发现队列的单变量分析,没有突变显示出统计学意义。
为了解决这个障碍,我们将每个样本的突变分为四种不同的功能级别,基于它们与公共可用热点的匹配及其功能注释(实验部分),并基于一个假设,即在癌细胞进化过程中,相同功能级别的突变可以近似相等。然后我们用两个数字特征来表示每个类别,即突变的计数和突变的最大变异等位基因频率。这个过程将聚集样本的突变谱组合成八个数字特征(表S5,支持信息)。基于这些特征的建模,SVM在发现队列中进行的AUC=0.54(图2a)。
为了了解cfDNA突变谱显著低效的原因,我们进一步评估了配对肿瘤血浆样本之间的突变一致性,基于额外的55个肿瘤测序队列(26个良性和29个恶性)。在29个恶性肿瘤样本中检测到的60个突变中,只有1个与相应配对的血浆样本中检测到的268个突变一致,而在26个良性肿瘤样本的31个突变中,只有2个与血浆中的288个突变一致。这表明,在我们的具体应用中,在血浆中检测到的突变与我们特别感兴趣的病变相关的特异性较差,这突出了cfDNA突变分析技术的警告,这不仅是因为该技术的灵敏度有限,还因为癌细胞形成和进化的复杂性。
应用cfDNA甲基化标志物预测PN恶性程度
在GeneCast生物技术有限公司使用基于捕获的NGS小组进行cfDNA甲基化分析,该小组主要基于公开可获得的癌症基因组图谱(TCGA)数据集设计。使用发现集上的数据(表S6,支持信息),甲基化的CpG位点首先被聚为697个甲基化相关块(MCB),用于特征表示(实验部分)。43个MCB在发现队列中具有统计学意义(表S7,支持信息),其中30个通过机器学习被选为多变量预测因子。
机构评美联储利率决议:美国联邦基金利率期货定价美国2023年“硬着陆”:9月22日消息,在美联储的鹰派经济预测公布后,联邦基金利率期货立即上扬以反映新的预测,目前定价2022年底利率升至4.3%,2023年3月达4.6%。但在2023年5月之后,联邦基金利率期货定价利率在2023年底前降至4.25%。
市场实际上是在为美联储的加息定价,但随后有可能出现硬着陆,迫使美联储在2023年降息。美国2年期和10年期国债收益率倒挂幅度扩大至52个基点,也证实了这一点。10年期收益率甚至在声明后略微走低。(金十)[2022/9/22 7:13:02]
综合多种分析试验预测PN恶性程度
对所有四个模型对发现队列的预测进行并列比较,发现在每个样本上,大多数预测是一致的,但也有一些是不一致的。借用“多数投票”的概念,我们通过随后的加权平均方法(实验部分)整合了所有模型的预测输出。伯努利泊素贝叶斯(BernoulliNaiveBayesian,BNB)学习模型在发现队列上进行训练,每个模型的预测输出作为其输入,样本的病理分类作为期望结果。此后,综合多分析BNB模型在发现队列上实现了AUC=0.85的显著改进(图2a)。
有趣的是,观察到基于贝叶斯的模型比它的任何组件模型都有更好的表现。虽然患者临床信息(患者年龄)和蛋白质癌生物标记物平台显示的特异性不能令人满意,而且DNA突变平台的灵敏度很低,但通过数学集成,它们仍然有助于在DNA甲基化平台上实现进一步的性能提升,呼应了一句古老的谚语:“两只手都比一只手好”,并突显了多组学分子检测在解决高度复杂的临床挑战(如PN恶性评估)中的重要性。然而,对于机器学习方法论研究人员来说,集成模型的改进性能似乎并不令人惊讶。本质上,我们研究中的BNB模型被用作堆叠集成分类器。
以前的研究已经证明,如果第一层输入分类器具有有限的相关性并相互补充,在我们的情况下,第二层集成分类器将能够平均来自不同模型的噪声,从而增强可概括的信号,从而产生更高的准确度。对整合模型的中间权重数据的进一步研究表明,该模型对蛋白质生物标志物(平均值=0.68)和cfDNA突变(0.71)的重要性权重明显低于对cfDNA甲基化(0.74)和临床特征(0.76)的重要性权重(图S3,支持信息),这与我们的研究和以前的报告中每个单独模型的表现基本一致。
PN恶性标志物和预测模型的独立验证
通过每个测试平台确定的统计标记,以及使用发现队列上的样本建立的多变量和多分析模型,我们进一步以29名患者的独立验证队列(14名良性患者和15名恶性患者)为基准。基于最终整合模型的发现队列的AUC值为0.85时,并假设α为0.05时,对AUC值的显著性进行统计检验的功率分析需要最少的11个良性样本和11个恶性样本才能达到0.9%的足够功率。
单变量临床特征,患者年龄,在AUC=0.73(图2b)的验证队列(表S1b,支持信息)上总体上保持其预测能力,在截止年龄=54(图S1,支持信息)的情况下,其敏感性为73.3%,特异性为64.3%。年龄界限在发现队列中确定,以优化预测模型的性能(以灵敏度+特异度衡量)。
在蛋白质癌症生物标志物平台上,三个选定的标志物(分别为CEA、CYFRA21-1和SCC)显示了独立验证群组(可测试的S3b,支持信息)的某些单变量预测能力下降,发现群组的AUC分别从0.72、0.68和0.67下降到验证群组的0.54、0.52和0.66。然而,他们的联合多变量预测更稳定,从发现队列的AUC=0.71到验证队列的AUC=0.67(图2b),使用优化的SVM预测得分截止值0.670,对应于60%的敏感性和71.4%的特异性,并反映出相对于单个蛋白质生物标志物的性能再现性略有改善。值得一提的是,我们观察到多个蛋白质生物标记的算法组合优于每个单独的生物标记,这与以前的研究一致,例如用于肺结节管理的Xpressys13-蛋白质分类器,其诊断信息的一致性约为10%(尤登指数)。
Gitcoin宣布暂停Tornado Cash赠款:8月9日消息,Gitcoin官方发推表示:“对Tornado Cash被制裁感到非常难过,已暂停Tornado Cash赠款,但相信保护隐私的工具对所有守法的元宇宙公民来说是至关重要的。”
注:Tornado Cash是早期Gitcoin Grants的受赠者。
金色财经此前消息,美国财政部将Tornado Cash列入制裁名单。[2022/8/9 12:12:17]
发现队列中受低AUC=0.54影响的cfDNA突变模型在独立验证队列中保持相同的AUC=0.62水平(图2b;这使得难以平衡预测灵敏度和特异性,使用0.660的优化截止阈值作为预测输出分数,得到灵敏度=80%和特异性=42.9%。
cfDNA甲基化模型在验证群组中也显示出一定的性能下降,从发现群组的AUC=0.81下降到验证群组的AUC=0.72(图2b;测试能力S6b,支持信息),使用0.606的优化预测得分截止值,其转化为灵敏度=93.3%和特异性=42.9%。然而,这种情况在临床上被认为是令人满意的。
为了进一步交叉验证基于cfDNA的MCB特征,我们对57名同意额外组织测序的发现和验证队列中的患者进行了独立的组织DNA(TDNA)甲基化测序(27例良性和30例恶性;表S8,支持信息),并根据Wilcoxon检验评估每个MCB的统计学意义(图S2a,支持信息)。在大多数MCB上,tDNA图谱显示良性和恶性组之间的差异高于cfDNA,这表明这些MCB选择的是恶性肿瘤的特异性特征。同时,cfDNA图谱显示与tDNA的皮尔逊相关系数高达0.84(图S2B,支持信息),有力地支持了基于cfDNA的MCB测量确实主要来源于他们配对的组织样本。
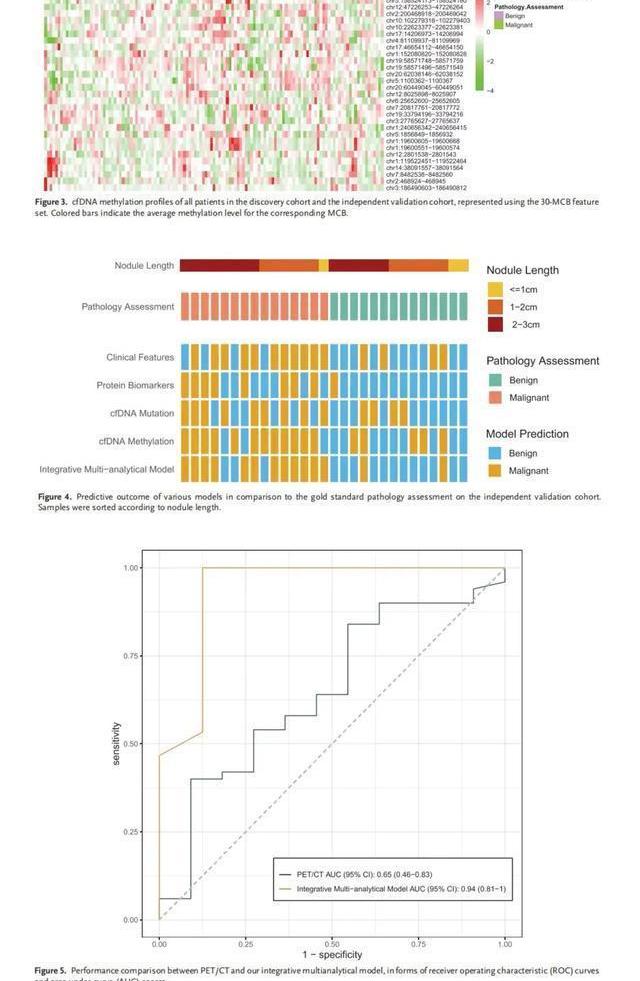
最后,尽管每个单独测试平台的预测模型的性能波动程度不同,但综合多分析模型在验证队列上的AUC值为0.86时(与发现队列上的AUC值为0.85时相比)(图2b),在预测分界值为0.761的情况下,对应的灵敏度=80%和特异度=85.7%,在灵敏度和特异度之间取得了令人满意的平衡,总体上显著优于任何单个测试平台。为了进一步了解综合模型的预测是如何与每个单独的模型叠加在一起的,我们将它们在每个验证上的预测输出(根据前面提到的优化的截止阈值在良性/恶性方面)与黄金标准的病理评估进行了比较(图4)。很明显,在四个个体模型做出相互矛盾预测的大多数样本(24个样本中的19个)上,综合模型能够更全面地将每个个体模型的输出组合成与病理评估相匹配的正确预测,证明了前面提到的“两只手比一只手好”的比喻。
综合多元分析模型的性能与结节大小的相关性
由于广泛观察到血液中循环肿瘤DNA的量与癌症的阶段和肿瘤体积呈正相关,我们根据三个不同的结节长度范围,即分别<=1、>1<=2和>2<=3,研究了恶性样品的平均提取的cfDNA量(标准化为全血的ngmL)和整合模型的性能(表S9,支持信息)。
总的来说,我们的数据确实支持了结核大小和结核脱氧核糖核酸数量之间的相关性,发现组群的平均提取的结核脱氧核糖核酸数量分别从551纳克/毫升1(1厘米≤1厘米)变为613.35纳克/毫升1(1-2厘米)和625.71纳克/毫升1(2-3厘米);独立验证队列分别为858、703.33和1015.75纳克/毫升。然而,综合模型的表现,无论是用AUC、灵敏度还是特异性来衡量,尽管显示出一定程度的波动,但不支持这种正相关性(表S9,支持信息)。虽然可以说这可能是由于我们的研究中队列规模相对较小,未能揭示明确的统计趋势,但我们怀疑这也支持了我们早期的观察,即结节大小(因此cfDNA数量)不是PN恶性肿瘤的强临床预测因素,这进一步加强了我们的信念,即分子检测可以提供对PN细胞组成及其恶性肿瘤的更全面的理解,而不是成像本身。此外,我们的综合多分析分子测试方法已经达到了一个灵敏度水平,通常不受分子大小的影响。这在图4中也很明显,其中综合模型的性能没有显示不同结节大小样本的统计偏差。
Alameda Research:如果Voyager可以退回抵押物,将偿还贷款:7月8日消息,Alameda Research 在社交媒体上表示,只要 Voyager 能够归还抵押品,我们很乐意归还Voyager贷款并取回我们的抵押品。
此前消息,Voyager提交给纽约地方法院的破产申请第13页上的表格显示,Alameda Research欠Voyager3.77亿美元,利率为1%至5%。根据文件第119页上Voyager最大的无担保索赔清单,未偿余额包括一笔7500万美元的无担保贷款。[2022/7/8 1:59:34]
综合多分析模型与正电子发射断层扫描在结核瘤与恶性结节鉴别中的比较
利用18F-氟脱氧葡萄糖正电子发射断层扫描/计算机断层扫描进行分子/解剖成像已被广泛认为是检测、识别和分期肺癌的方法。它提供了最大标准摄取值(SUVmax)>2.5的标准摄取值,通常用作区分肺部恶性肿瘤和良性疾病的截止值。作为基线参考,我们研究了一个由61名接受正电子发射断层扫描/计算机断层扫描的患者组成的独立队列,其中50名后来经病理证实为恶性结节,11名为结核瘤(支持信息,表S10)。恶性结节的SURVAMX一般高于结核瘤(7.18±3.82vs5.36±3.78),但无统计学意义(p=0.264,t=1.147)。值得注意的是,如果仅将SURVAMX用于决策,SURVAMX>2.5的11个结核瘤样本中有9个将被误诊为恶性,对应于AUC=0.65,灵敏度=90%,特异性=9.1%(图5)。相比之下,对于我们独立验证队列中患有恶性结节(15)或结核瘤(8)的23名患者,我们的综合多分析模型的AUC=0.94,敏感性=80%,特异性=87.5%(图5;和测试S11,支持信息)。尽管这两组绩效指标基于两个不同的队列,由于我们队列中没有患者进行正电子发射断层扫描/计算机断层扫描的限制,并且相对较小的队列没有统计学意义,但它们仍然提供了一些有希望的基线理解,说明我们的方法优于正电子发射断层扫描/计算机断层扫描。
建议方法的成本和可用性分析
虽然我们的手稿主要集中在建议方法的临床有效性上,但在我们评估其临床实用性之前,不应忽视其现实世界的经济意义。由于我们研究的主要目标是减少对良性肺结节患者的过度治疗(不必要的手术),并且我们方法中的抽血比侵入性肺叶切除术或叶下切除术对患者更有吸引力,如果我们联合分子测试的总货币成本低于手术,我们的多组学方法将至少在财务上对特定的良性患者有利(除了所有其他与医疗保健相关的益处)。如果整个受试患者群体的总检测成本低于所有良性患者的手术成本,我们的方案将在总体临床上受益。在我们的研究中,基于我们测试的材料和人工成本以及估计的工业利润,病人的假设测试成本仍然只有手术围手术期总费用的大约44%(4000美元对9000美元)。尽管如此,这还是基于我们最初实验设计中用于标记发现的相对较大的NGS面板。一旦我们选择的少量预测性DNA甲基化MCB标志物和蛋白质癌症生物标志物在未来的临床试验中得到临床验证,就有望进一步降低测试成本。因此,我们的方法不仅在临床上可行,而且在经济上负担得起,具有巨大的潜力。
患者花费的第二个方面是时间——以及与之密切相关的测试可用性——他们在等待测试结果和手术的决定。就目前而言,与NGS相关的分子工作台工作的复杂性几乎肯定保证了必要的(而不是更容易获得和更快速的本地现场护理设备),这通常需要至少几个工作日的周转时间(TAT)。幸运的是,近年来NGS的技术和物流进步以及分子检测表明,这种水平的检测不会成为临床决策过程中的重大瓶颈,因为外科手术的实际准备时间通常会超过这种检测。
结论和今后的工作
LDCT的高假阳性率仍然是肺部PNs诊断的一个挑战,在作者的临床环境中结核瘤患者的相对高患病率进一步加剧了这一挑战。我们的研究采用了临床特征、蛋白质癌症生物标志物、cfDNA突变和cfDNA甲基化谱来获得PNs的综合谱,并建立了一个综合的多分析模型来从CT诊断肺结节中检测恶性肺结节。在98名患者的发现队列中,该模型显示出区分肺癌患者和良性结节的高鉴别能力(AUC=0.85),在29名患者的验证队列中,AUC=0.86进一步得到独立验证。综合模型明显优于基于任何单独测试平台的模型。此外,该模型在结核瘤和恶性肺结节之间的诊断中表现出显著更好的性能(AUC=0.94),这对于正电子发射断层扫描来说是一项困难的任务(AUC=0.65)。总之,我们的研究为肺癌的无创诊断提供了一种有效的新方法,并显示了其在实际临床应用中的潜力。我们研究的附加价值在肺癌诊断的文献中已经报道了不同组的cfDNA甲基化标记。例如lian等人的9个cfDNA甲基化位点和chen等人的三基因组合模型,但是后者的灵敏度和特异性随着结节大小的减小而急剧下降。我们的研究使用基因无关的MCB作为标记。与以前的研究相比,30-MCBs标记集覆盖了更大的基因组区域,这可能是我们的最终模型无论结节大小如何都保持相对高的敏感性和特异性的原因,因为CpG岛胞嘧啶的甲基化沉默了数百个参与肺癌发生和发展的基因。从数据角度来看,由于每个MCB标记都是多个CpG岛的合并和算术平均值,因此实践减少了由于过度拟合而导致的模型方差,并提高了预测模型的稳健性。类似的概念,当应用于cfDNA突变分析时,也显示了它在处理稀疏、低流行点突变数据方面的有效性。我们的研究可能是第一次将所有临床特征、蛋白质癌症生物标志物、cfDNA突变和cfDNA甲基化结合起来,以获得对PNs更全面的理解,从而实现预测灵敏度和特异性的更好平衡。在我们的研究中,基于贝叶斯的综合多分析模型优于任何单个模型,并在发现和独立验证队列中保持了相当稳定和平衡的敏感性和特异性。我们的研究清楚地显示了综合多组学方法在解决具有挑战性的临床应用方面的优势。未来工作我们的研究有几个局限性,值得今后的工作。首先,纯磨玻璃结节患者不包括在这一阶段,这仍是一项未来的工作。第二,我们的模型仅限于经CT筛查的肺结节患者,目的是辅助CT诊断。它在健康人群癌症筛查中的表现尚待评估。第三,我们的模型用于预测恶性结节和浸润性癌,其对浸润前病变(如微创腺癌和原位腺癌)的诊断效果需要进一步验证。最后,尽管已经在29名患者队列中进行了独立验证,但我们模型的预测性能以及我们方法的有效性仍有待在更大和更多样化的患者群体中进一步验证,这项工作已经在进行中,预计将在后续手稿中报告。
实验部分
大量采集:抽取10mL血液,室温保存在无细胞DNA存储管(PET)(cwBiotechCatBillions项目组CWY025M(CwBiotechCatBillions项目组A29319)提取cfDNA。用TIAANAMP血液DNA试剂盒(TIANGEN)从外周血单个核细胞中提取生殖系DNA。DNA和甲基化测序文库的制备都需要至少10ngcfDNA。采用MagenCatBillions项目组D6323-02B)从恶性和良性FFPE肺组织标本中提取组织基因组DNA(GDNA)。制备甲基化测序文库至少需要100nggDNA。CfDNA突变分析:cfDNA突变测序基于GeneCast生物技术有限公司实验室开发的捕获小组测试,该测试已根据美国病理学家学会(CAP)的指导原则进行了内部验证。简而言之,利用KAPAHyperPrepKit(Roche),基于具有唯一分子识别符(UMIS)的接头,构建了cfDNA突变测序文库。在接头连接后,用xGen杂交和洗涤试剂盒(IDT)将DNA杂交到自己设计的124kb大小的29基因突变板上。使用QubitdsDNAHSAssayKit(ThermoFisherCatBillions项目组5634253001)与捕获板杂交。纯化是使用SeqCapEZ纯捕获珠试剂盒(CatBillions项目组Q32854)进行定量。甲基化文库在IlluminaXten测序系统上测序,阅读长度为151bp。甲基化数据处理:使用内部管道处理甲基化测序读数,该管道包含用于解复用的Illuminabcl2fastq、用于基础质量修整的Trimmomatic、用于参考基因组作图的Bimark、Bimark、Samtools和用于映射读数重复数据删除、排序和剪切的BaMutil(https://github.com/statgen/bamUtil)。映射质量小于20且转化率小于95%的读取被过滤掉。CpG位点的甲基化水平被BiSnP以β值的形式称为。为了进行质量控制,深度小于100倍的CpG位点被去除,支持甲基化阅读的β值小于2的位点被替换为0。MCB被定义为包含至少3个CpG位点的基因组区域,每个位点与其相邻位点的距离<=100bp,皮尔逊相关系数>=0.9。分别为发现队列中的良性和恶性组计算每对相邻CpG位点之间的相关性。只考虑两组中相关性高的区块。根据该标准生成了697个多氯联苯,包括4678个氯化石蜡位点。MCB中CpG位点的平均β值被用作MCB的甲基化水平。标记物选择的单变量分析:对于基于临床特征、癌症蛋白质生物标记物和cfDNA甲基化MCBs的数据,在发现队列中进行了六个单变量测试,包括方差分析、费希尔精确测试、卡方测试、威尔科克森秩和测试、曼-惠特尼测试和学生t-测试,以评估每个变量在最大和最小样本组之间的区分能力。每个测试中p<0.1被认为具有统计学意义。一个变量只有在六个测试中的至少四个测试中具有统计显著性时,才被视为候选标记。单变量预测AUC也是为参考目的而计算的,但不用作标记物选择标准。所有单变量测试均使用R版本3.6.3(https://www.R-project.org/)进行。结节恶性肿瘤分类的机器学习:每个数值数据点x首先被标准化为log2(x+1),用于异常值控制和高斯分布近似。缺失的数据点用发现队列中相应特征读数的中值估算。数据最终使用z评分进行标准化,z评分计算为z=(X–mean(X))/STD(X),其中X是发现队列中X的所有读数。对于甲基化MCB特征,使用交叉验证递归特征消除(RFECV)进行额外的特征选择,以优化发现队列模型的准确性。这个过程是通过基于机器学习包scikit-learn的内部Python(3.7版)脚本实现的。每一轮RFECV过程都通过递归地从候选特征集中移除排名较低的特征来工作,并通过交叉验证来评估剩余特征的性能,直到实现优化的性能。通过20个分层的混合分割交叉验证器,10个分割迭代和20-40%的测试大小范围,30兆字节的初始筛选43个日期被选择作为后续培训的一致特征集。一个基于SVM的分类器在同一个内部Python软件包中实现,并基于13倍交叉验证对其性能进行了评估。SVM通过优化预先定义的超平面类型(称为核)的参数来工作,该超平面将研究中的良性和恶性分类分开,以最大化所有训练数据点到超平面之间的总距离,换句话说,优化两个分类的分开。研究中使用了一个简单的线性核。在每个文件夹中,超参数优化通过交叉验证网格穷举搜索进行调整,随机选择发现群组中的60%样本进行训练,剩余的40%样本进行测试,并用最佳得分参数重新调整训练群组。综合多分析模型:每个个体模型在每个研究领域的预测输出(即临床特征、癌症蛋白标志物、cfDNA突变和cfDNA甲基化)由恶性概率分数组成。这四个分数被用作随后的BNB模型的输入,该模型被训练来优化对每个单独模型的“投票权”(即,重要性权重)的分配,以便适合每个数据点的已知分类标签。BNB是一种基于概率论和贝叶斯定理的概率算法,用于预测属于预定义类别的未知输入的概率。在lay语言中,由于训练数据集中每个个体分类器的性能(即,当分类器输出某个输出分数时,输入样本的恶性被正确预测的概率)是已知的,因此能够基于所有四个分类器的预测分数的组合导出加权平均公式来计算输入样本恶性的概率。该算法是在上述相同的内部Python工具包中实现的。统计分析:由于研究的前瞻性观察性质,没有进行统计分析来确定发现队列的规模,这在很大程度上受样本可用性的影响。基于预测标记物和模型的性能分析,停止患者登记以进行发现,共同影响整个项目时间表。基于Obuchowski和McCLISH的模型,使用PASS2020软件的单ROC曲线功率分析模块进行功率分析,以确定独立验证群组的规模。
各位玩DIY的小伙伴,最近心情应该不错。虽然在正规渠道,比如京东、天猫上,显卡、硬盘等产品的价格还是偏高,但是和前两个月相比,已经无法同日而语,不但产品的数量相对充足,价格也下来了不少.
1900/1/1 0:00:00鞭牛士报道欧易OKEx早讯将在每日早间推送最新产业动态及行情,帮助投资人快速了解行业热点,把握每一个投资机会。 行情播报 6月3日讯,今日加密货币市场整体小幅下跌.
1900/1/1 0:00:00最重要但双重优势的叙述之一是“比特币是数字黄金”。在这个非常特别的比特币杂志播客中,CK与投资者、比特币思想家和作家AaronSegal坐在一起.
1900/1/1 0:00:00数字人民币正加速融入居民生活的各个方面。近期海南银行、西安银行等金融机构也通过接入大行系统,加入数字人民币试点。目前,数字人民币已经进入面向公众的测试阶段,其双层运营机制更加清晰.
1900/1/1 0:00:005月24日消息,在经过又一轮抛售后,全球最大加密货币比特币的价格在周日大跌13%,较今年的价格高点已下跌近50%.
1900/1/1 0:00:00大家好,我是爱研究学区的木木老师。新的开学季即将到来,今天我们就来摆哈儿,重庆七龙珠名校之一的南开中学.
1900/1/1 0:00:00