作者:SrinivasGumparthi博士,VenkataVaraPrasad博士
来源:SSRN
发布:2022.08.31
摘要
目的:股票价格预测一直作为一门研究课题,因为它在国家宏观经济中具有重要的作用。很难用一组特定的公式写下股票的未来价值。当我们预测一只股票的未来价格时,许多因素都会出现。其中最重要的是历史价格和成交量数据。
方法:随着机器学习的兴起,人们提出了多种预测股票价格的方法。目前,已开发了RNN、LSTM、CNN滑动窗口等各种模型,但都不够精确。这项工作的兴趣在于预测股票的价格,以及比较使用两种算法,即KalmamFilters和XGBoost,并获得结果。KalmamFilters本质上是递归的,并使用反馈机制进行误差校正。这种修正能让他们做出准确的预测,因为它们可以将市场波动考虑在内,而XGBoost对于非线性数据集来说是一种很有前途的技术,可以通过检测数据中的模式和关系来收集知识。此外,XGBoost还能有效地捕获特征的时间依赖性。
新颖性:最后,结合KalmamFilters和XGBoost开发了一个Hybrid模型,给出了未来投资和股票预测所需的完美预测。与KalmamFilters和Hybrid模型相比,XGBoost的平均准确率更高。
研究结果:混合模型似乎能准确地预测样本的未来趋势,但并不是对所有样本都能做到这一点。XGBoost模型对NSE数据集的平均准确率为88.66%,对NYSE数据集的平均准确率为90.11%。KalmamFilter模型对NSE数据集的平均准确率为89.09,对NYSE数据集的平均准确率为64.96。该Hybrid模型对NSE数据集的平均准确率为76.79%,对NYSE数据集的平均准确率为70.91%。然而,对于个股,Hybrid模型表现优于XGBoost和KalmamFilter。
关键字:XGBoost,KalmanFilter,Hybrid模型,NSE,NYSE,市场情绪
1.介绍
如今,股票市场已成为大家的一个重要投资领域,很多普通人也对股票投资很感兴趣。受环境、和其他社会因素的影响,股票市场价格波动很大。因此,有必要对股票价格预测进行广泛分析。早期的统计模型和机器学习模型用于股票价格的预测。但考虑到历史数据,数据量越来越大,这些模型在股票价格预测方面的准确性逐渐下降。因此,在当前的工作中,作者提出了一种结合统计和机器学习模型的混合模型。利用Kalmanfilter和XGBoost的优点来提高预测准确度。
很多研究人员使用各种统计和机器学习模型来解决这个问题。很少有人研究这些模型的组合,也很少有人给出印度股市带来的显著结果。Chatziset等人的研究旨在利用机器学习技术预测股市危机事件。该方法是基于寻找股票市场崩盘事件在不同时间框架的概率。考察了股票、债券和货币市场之间的交叉传染效应。使用模型预测日收益,利用对数收益的平方计算日波动率。XGBoost在1天和20天内都有最佳的经验表现。
澳大利亚芒果生产商Manbulloo利用区块链技术进行供应链溯源:经过为期两年半的试点项目,澳大利亚一家芒果生产商正在扩大区块链技术在供应链追溯中的应用。据北澳大利亚发展合作研究中心(CRCNA)称,该组织与澳大利亚主要芒果生产商Manbulloo和可追溯软件公司Trust Provenance达成合作,测试了一项贯穿其在昆士兰和北领地的供应链和配送中心的供应链管理计划。该项目于2018年启动,通过在芒果包装箱中安装传感器,除了监测温度、湿度和运输时间外,还可以追踪芒果的移动情况。(Cointelegraph)[2020/10/28]
Sen等人使用具有反向传播算法的ANN作为训练阶段,并使用多层前馈网络作为预测股票价格的网络模型。研究了一种基于ANN的股票交易决策支持系统。本文还讨论了基于决策过程的神经网络的研究进展。该模型随输入值和时期的不同组合而变化。它输出性能曲线、误差曲线和输出图形。验证效果良好,回归值为0.996。
Dey等人将各种深度学习算法与XGBoost进行比较,以预测Yahoo数据集的股票市场回报。预测周期分别为28天、60天和90天。已经计算了每一项的准确性、预测性、召回率和特异性。绘制每个模型的假阳性率。
Karyaet等人在论文中,采用集合卡尔曼滤波平方根法和集合卡尔曼滤波法对股票价格进行预测。模拟结果表明,EnKF方法的估计结果比EnKF-SR方法更精确,即EnKF方法的估计误差约为0.2%,而EnKF-SR方法的估计误差为2.6%,。
Mortezaet等人的项目,试图在NSE上使用机器学习技术来预测股票的未来价格,他们使用线性回归和SVM回归。线性回归将使用股票前一天的收盘价来预测股票第二天的开盘价。SVM回归将用于预测第二天股票的收盘价和开盘价之间的差值。外汇汇率、NSE指数、移动平均线、相对强弱指数等外部因素,被用来获得最大的准确性。
DevShah等人在论文中,讨论了股票市场分析的技术和基本方法。在技术分析中详细讨论了统计、机器学习、模式识别、情感分析和混合技术,还考虑了算法交易。作者总结说,包含混合和统计的机器学习技术,将产生更好的结果。人工神经网络是人工智能的一部分,是一种识别数据中隐藏的、未知的、适合股票市场预测模式的常用方法。所选股票的历史数据用于建立和训练模型。
Song等人在论文中,将RNN-LSTM模型与SVM和XGBoost进行了比较。数据集是通过应用Python库从GoogleFinance的API中获得的。选择了20家在NASDAQ和NYSE交易的公司。考虑了RSI、ADX和抛物线SAR等指标。通过绘制测试集误差图来比较结果。
Wanjawaet等人的研究,提出使用具有多层感知器的前馈人工神经网络,通过反向传播来预测股票价格。该模型分4个阶段进行迭代。数据集来自内罗毕证券交易所和NYSE。通过改变隐藏层和感知的数量进行调优。每个调优实验都基于前一个实验模型进行的。最终模型的配置比为5:21:21:1,使用80%的可用数据进行训练。采用均方根误差作为参数,将获得的结果与原始结果进行比较。结果表明,该模型对股票价格的预测具有较好的效果。
国家新闻出版署:引导发行企业充分利用区块链等技术:国家新闻出版署发布关于“支持出版物发行企业抓好疫情防控有序恢复经营”的通知。通知指出,各级新闻出版行政部门要认真贯彻落实新发展理念,支持、引导发行企业转型升级,建立完善社会效益和经济效益统一体制机制,应用新技术新业态新模式。
要推动技术模式创新。引导发行企业充分利用互联网、物联网、云计算、大数据、人工智能、区块链、数字印刷等新技术,促进科技成果转化应用,推动发行企业转变发展方式、实现动能转换,加快经营业态和服务模式创新。(中国新闻出版广电报)[2020/3/19]
徐等人进行了比较文献调查,证明ANN比SVM预测更准确。使用反向传播训练若干个前馈ANN。该评估是在NASDAQ证券交易所进行的,采用了6个月的数据集。模型的输入是短期历史股票价格和每周的天数。通过对每个隐藏层中神经元数目和设置不同的值,来优化神经网络的结构。
郑红英等人提出了一种新的深度学习模型-随机长短期记忆,旨在防止过拟合。该模型由Modaugnet-C框架和另一个用于预测的LSTM模块组成,Modaugnet-C框架通过一个LSTM模块和另一个LSTM模块来增强单个LSTM模块的潜力,其中一个LSTM模块可以使用额外的增强数据来降低过拟合的风险,这些数据与用于预测的股票数据有很强的相关性。这在SSEC和S&P500数据集上进行了测试,该模型在准确性上优于其他模型。
WidodoBudiharto提出了一个模型,该模型结合了LSTM和基于R语言的统计计算,用于预测Covid-19大流行期间印度尼西亚交易所的股票。该模型在预测不到一年的短期数据时表现良好,准确率达94.5%,超过了长期数据的预测。
SalvatoreM.Cartaet等人使用机器学习方法,借助决策树的二元分类技术来衡量未来股票价格波动的幅度。这些词汇是从全球发表的文章、行业相关新闻等中识别和生成的。这些数据将与提取的特征一起输入到预测模型。这在S&P500指数公司进行了测试,但准确率只有50-60%。
Milad等人比较了人工神经网络和启发式算法与传统的时间序列模型来预测股票价格。这些模型用于各种国际指数,如Nasdaq指数、S&P500指数和DJI指数。与时间序列模型比较,ANN模型的误差最小,预测效果更好。
Zelingheret等人测试使用各种机器学习模型来预测玉米价格的波动。他们考虑了线性模型,分类和回归树,随机森林,梯度聚类。这些方法基于均方根误差、漏一交叉验证等,证明对玉米价格预测有效。
Chetan等人使用多种机器学习算法进行了比较研究,并结合情绪分析来预测Covid-19大流行期间的股票价格,因为这个时期社交媒体存在大量情绪。在所考虑的模型中,逻辑回归模型表现最好,而KNN模型的准确性最低。
2.设计和方法
预测模型的架构图。首先清理从NSE获得的数据集,以检查空值,并获取从YahooFinance收集的市场情绪数据。然后对其进行预处理,以获得各种其他特征,例如调整后的闭合因子、闭合偏移、开启偏移、开启差、闭合差、高差和低差等。输入正在清理的库存数据。然后将该数据发送到三个模型中的每一个。在第一个模型——KalmanFilter,数据在每次迭代时都要经过预测和更新步骤。在预测步骤中,根据在前一时间步骤K-1更新的特征计算下一时间步骤K的收盘价。在更新步骤中,与前一时间步骤的预测相对应的特征被更新。在XGBoost中,数据集经历两个阶段——拟合和预测。在拟合阶段,该模型递归地构建各种决策树,将范围缩小到损失函数值最小的决策树。在预测阶段,使用此决策树进行下一步的预测。对于Hybrid模型,我们首先运行XGBoost算法来执行特征选择。这些特征输入到KalmanFilter,预测股票的收盘价。然后,我们执行输出分析以比较模型的结果。
动态 | 日本Recruit Holdings成立投资基金 专注于利用加密技术进行转账的企业:据日经新闻消息,日本上市公司Recruit Holdings昨日宣布已成立名为RSP Blockchain Tech Fund的新投资基金,该基金将专注于利用加密货币技术进行转账汇款的公司,基金规模为2500万美元,主要投资目标为海外初创企业。据此前消息,Beam透露其主网已获得该基金投资。[2019/2/19]
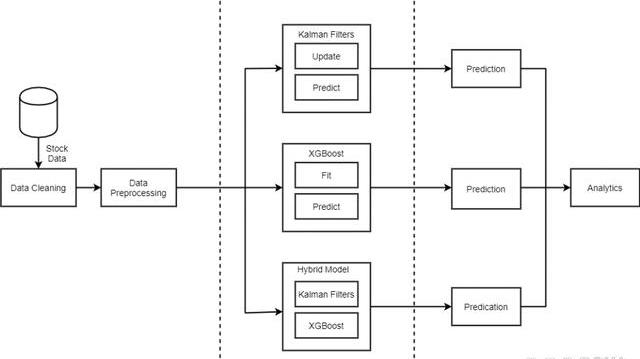
图1体系结构图
2.1KalmanFilter
在统计学中,KalmanFiltering是一种算法,使用一系列测量数据,包含随时间推移观察到的统计噪声和不准确性。该算法对未知变量的估计往往比仅基于单一特征的估计更准确。它估计每个时间段变量的联合概率分布。KalmanFilter是以RudolfE.Kalman名字命名的,他是该理论的主要开发者之一。
Xk=Fk*Xk+BkUk+Wk
Fk是应用于先前状态Xk-1的状态转换模型,
Bk是应用于控制向量Uk的控制输入模型,
Wk是假定从零均值多元正态分布中提取的过程噪声。
2.2XGBoost
XGBoost是一种以开源方式实现的高效且流行的梯度增强树算法。梯度提升是一种监督学习算法。XGBoost试图通过组合一组更简单、更弱的模型的估计值来准确预测目标变量。
XGBoost是一种集成学习方法。集成学习提供了一种系统的解决方案,结合了多个学习者的预测能力。结果是一个单一的模型,它来自多个模型的聚合输出。形成集成的基本学习者,可以来自相同的学习算法或不同的学习算法。广泛使用的集成学习者是Bagging和Boosting。XGBoost最主要的用途是决策树,其次是统计模型。
当使用梯度提升进行回归时,每个回归树都将一个数据点映射到它的一个连续叶子上,且弱学习者是回归树。XGBoost最小化了一个正则化目标函数,该目标函数结合了凸损失函数和模型复杂性的惩罚项。训练迭代地进行,添加新树来预测先前树的残差,然后将这些树与先前树组合起来,以进行最终的预测。被称之为梯度提升,是因为它使用梯度下降算法来最小化添加新模型时的损失。
3.数据集及其实现
3.1数据集
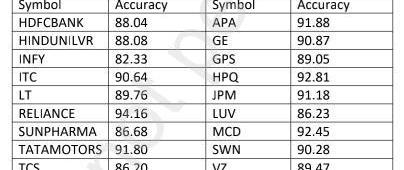
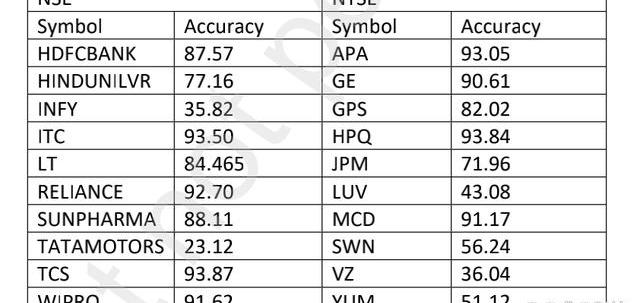
该数据集包含来自纽约证券交易所和国家证券交易所的10个脚本的股票价值。股票的名称及其符号如下表1所示。
表1:显示了所考虑的数据集
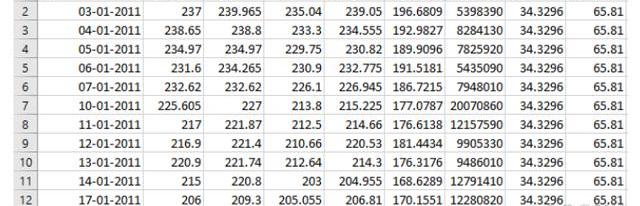
HDFCBANK数据的样本如表2所示。它由开盘价、收盘价、最高价、最低价、交易量、调整后收盘价、每股收益、市盈率等列组成。我们既考虑了股票的基本面,也考虑了市场情绪,这有助于我们更好地预测。
声音 | 阿里副总裁方建生:阿里希望利用区块链等技术帮扶农村地区发展:近日,广东省电商兴农扶贫大会暨农村电商高峰论坛在清远英德举行,会上启动了广东省电商兴农扶贫项目。阿里巴巴集团副总裁方建生在致辞中表示,阿里巴巴希望可以通过自身技术上的优势帮扶农村地区发展,将云计算、人工智能、区块链等方面的技术应用到农村、农业当中,希望从根本上改变我国农业低质低效、农村单调枯燥的现状。[2018/12/29]
表2:来自NSE的HDFC银行数据集
我们使用皮尔逊相关矩阵发现了每一对特征之间的数据相关性。如图2所示。数据关联有助于理解数据集中多个变量和属性之间的关系。使用相关性,我们可以获得一些见解,例如一个或多个属性依赖于另一个属性,或另一个属性的原因,以及一个或多个属性与其他属性相关联。

图2数据集中特征的相关性
对数据集进行预处理以获得其他特征,例如调整因子、调整闭合位移、开放位移、高差、低差、开放差和关闭差等特征。预处理后的数据集如表3所示。
表3:预处理的HDFC数据集
调整后的收盘价和开盘价有助于将前一天调整后的收盘价和开盘价与第二天调整后的收盘价和开盘价相关联。开盘价、最高价、最低价和收盘价分别乘以调整因子,使其与调整后的收盘价相对应。
PankajKumar博士的研究结果表明,每股收益是所选公司股票市场价格的可靠预测指标,市盈率对股票市场价格的预测有显著影响。因此,从整体上看,每股收益是A股市场价格表现的主要反映指标。
3.2KalmanFilter
3.2.1初始化
卡尔曼滤波器类被定义为数据成员F、H、Q、R和P初始化为单位矩阵和X-平均或预测状态估计。
3.2.2预测
该步骤必须预测系统的均值X和协方差P。当给定卡尔曼对象作为输入时,函数predict执行预测。
3.2.3更新
该步骤计算给定待更新的特征Z及其标准偏差R系统的均值X和协方差p。函数更新执行X,y的更新,S,K,P。矩阵乘法利用向量的点积。
对于每个时间步长K,执行预测和更新步骤以获得预测值。该预测数组由必须进行预测的日期相对应的收盘价组成。这些值取决于参数,如打开、高、低、调整关闭、调整关闭位移、开放位移、EPS、PE比率等。在这一步之后,我们必须通过对照地面实况来计算预测中的误差。对于此计算,我们使用绝对百分比误差的平均值,其计算公式为:error=*100/]*100)。预测图是在考虑的整个时期内绘制的。为此,我们使用Python中可用的matplotlib包。
路易斯安娜州司法部长开除并刑事调查几名涉嫌利用国家资源挖掘比特币的IT员工 员工却否认指控:美国路易斯安娜州司法部长将其办公室前任IT人员(包括一位被推翻的主管)开除,并正在对其进行刑事调查,指控他们利用国家资源开采比特币。据报道,司法部长办事处的路易斯安那州调查局在发现他们认为可能用于挖掘比特币的“硬件”后,对嫌疑人提出了质疑。目前尚未向公众透露发现了哪些设备。涉嫌挖掘比特币被解雇的员工包括系统管理员,服务台经理,诉讼支持协调员以及隶属于IT部门的人力资源人员。这些前雇员中有三位在接受采访The Advocate时否认了这些指控,称他们是由于司法部长办公室的误解而被解雇的。据当地新闻报道,被解雇的员工表示,因为电脑的能力有限,即使他们想,也无法使用办公室计算机来挖掘加密货币。他们解释说,挖掘比特币这样的活动很容易因计算过程中所需的大量电力而被检测到。[2018/3/2]
3.3XGBoost
下面将详细讨论所涉及的算法和XGBOOST算法的实现细节。该实现是在Anaconda框架下使用Python完成的。
3.3.1Bagging
尽管决策树是最容易解释的模型之一,但决策树表现出高度可变的行为。考虑将被随机分成两部分的单个训练数据集。每个部分将训练一个决策树以获得两个模型。当这两个模型都符合时,它们将产生不同的结果。由于这种行为,决策树被认为与高方差有关联。Bagging或Boosting聚合有助于减少任何学习者的差异。并行创建的几个决策树构成了Bagging技术的基础学习者。用替换后的样本数据对这些学习者进行训练。最终的预测输出是所有学习者的平均输出。
3.3.2Boosting
在Boosting中,所有的树都是按顺序构建的,这样每个后续的树都会减少前一棵树的错误。每棵树从它的前项中学习并更新错误。因此,所有后续的树将从错误的更新版本中学习。偏差很高的基础学习者是弱学习者,预测能力只比偶然猜测强一点点。每一个弱学习者都为预测提供了重要信息,从而通过组合这些弱学习者来产生一个强学习者。最后一个和最后的强学习者具有较低的偏差和方差。
与随机森林等Bagging技术形成鲜明对比的是,XGBoost中的Boosting模型利用了分裂次数较少的树。这样的小树是高度可解释的,因为树的深度非常小。迭代次数或树的数量、梯度提升的学习率和树的深度等参数,可以通过k-fold交叉验证等验证技术进行优化选择。过拟合是由于树太多造成的。因此,有必要谨慎选择助推的停止标准。
3.4HybridModel
HybridModel是统计模型,Kalmanfilter和机器学习模型XGBoost的组合。Hybrid模型有助于正确预测股票价值,提高各种数据集的准确性和一致性。当利益变量不能直接测量时,Kalmanfilters可以最优地估计感兴趣的变量,间接测量是可用的。对于这种间接测量,可以使用14个参数。通过特征提取,XGBoost算法在14个参数中根据权值取前5个参数。前5个参数因股票而异。将这5个参数输入Kalmanfilter,对未来股票价值进行预测,并提取输出。
通过在测试集中输入no,对以下每个模型进行测试,测试集包含400天的库存数据,预测必须在几天后进行。所有的模型都用两个不同的数据集进行了测试——一个由价格变动组成,另一个由价格变动和市场情绪组成。价格变动包括开盘价、最高价、最低价、收盘价、成交量、股息率、成交量等数据。市场情绪是指投资者对某一特定证券的整体心理。这是普通大众的感觉,通过证券交易的价格变动表现出来。极高的市盈率表示给定股票的价格很高,随时可能下跌。在这种情况下,可以说股票超买了。低市盈率表明对公司的业绩和未来缺乏信心。每股收益是指公司持有的每股股票的收益。它是衡量公司盈利能力的指标。通常优选较高的EPS。
3.4.1Kalmanfilter
下图描述了该模型在考虑市场情绪前后的HDFC银行数据集预测。我们可以看到,该模型在后一种情况下表现得更好。如图3所示,仅考虑价格变动,我们的准确率仅为88%。但如图4所示,考虑市场情绪后,我们的准确率为91.75%。准确率大大提高。
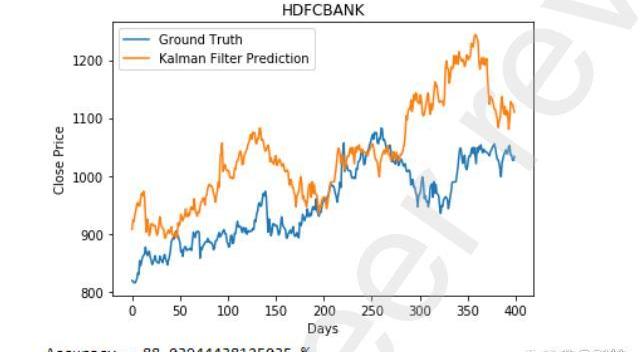
图3不考虑市场情绪的HDFC预测
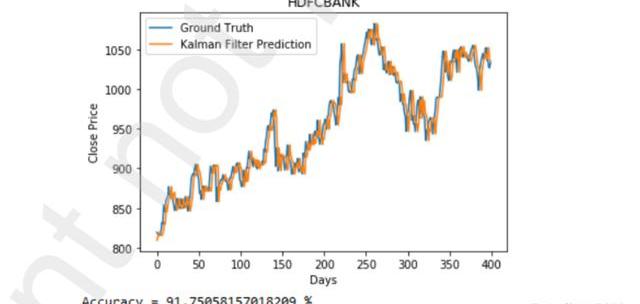
图4考虑市场情绪的HDFC预测
该模型还针对18个可用数据集中的其余数据集进行了测试,这些数据集总结在下表4中。
表4不同数据集的Kalmanfilter模型准确性
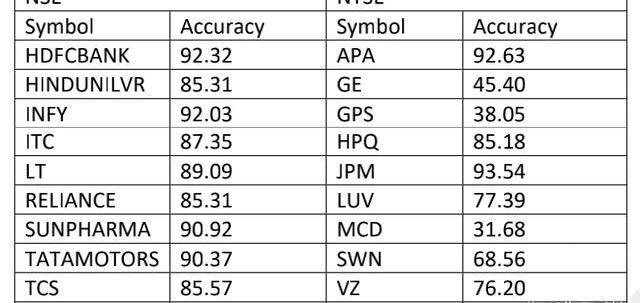
从上述结果中我们可以看出,该模型对NSE的各种数据集的表现是一致的,并且可以依赖该模型做出更好的预测,但对于NYSE,准确率并不一致且不高。
3.4.2XGBoost
XGBoost模型是为国家证券交易所的HDFC银行数据集和纽约证券交易所的JPMorgan数据集开发的。这些模型是在有市场情绪和没有市场情绪的情况下训练的。不同于KalmanFilters在加入市场情绪后会产生准确率和误差率的显著变化,XGBoost中的准确率和误差率保持不变。因此,在进一步的训练中考虑了市场情绪。在为数据建立模型后,JPMorgan
和HDFC银行的测试数据的准确率分别为91%和88%。

图5考虑市场情绪的HDFC数据集的准确性

图6考虑市场情绪的JPM数据集的准确性
图5和图6分别显示了测试HDFCBank和JPMorganandChase数据集时获得的准确性和误差。
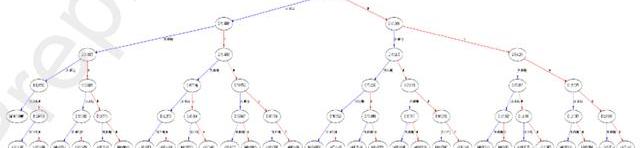
图7训练HDFC数据集时增强回归树的权重

图8训练JPM数据集时增强回归树的权重
图7和图8显示了在训练模型时获得的增强回归树的权重,然后用于进一步预测训练集。
该模型还针对18个可用数据集中的其余数据集进行了测试,这些数据集总结在下表5中。
表5XGBoost模型在不同数据集上的准确性
3.4.3Hybrid模型
两个不同公司股票的模型结果,如下所示。
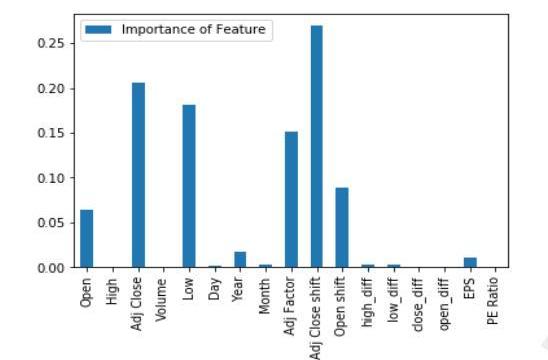
图9XGBoost为HDFC数据集发现的功能重要性
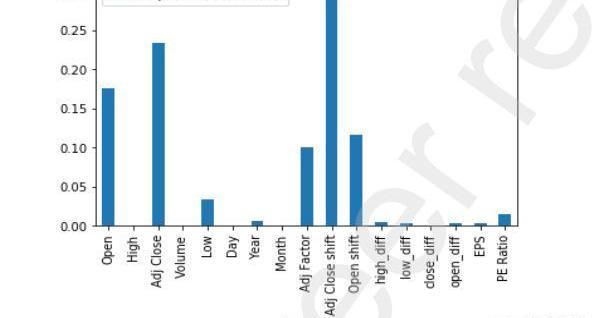
图10XGBoost为JPM数据集找到的功能重要性
从上面通过实现XGBoost算法获得的图9和图10中,我们可以找到预测时在增强回归树中起最重要作用的特征。我们只考虑上述步骤中的前5个特征,并将这些特征提供给KalmanFilter模型,以进行最终的股票价值预测。
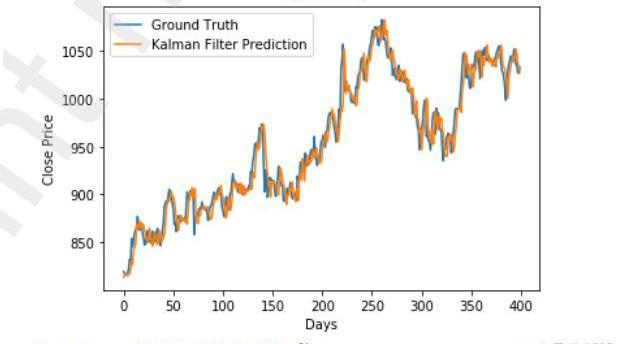
图11Hybrid模型对HDFC数据集的预测
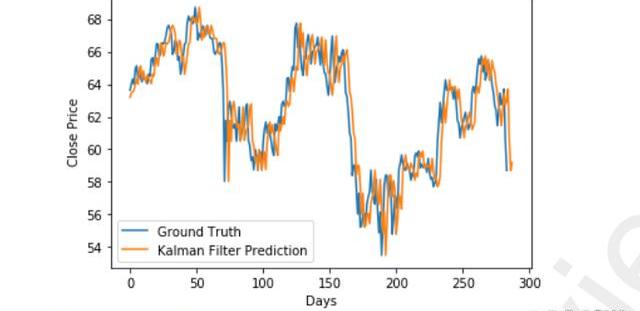
图12Hybrid模型对JPM数据集的预测
该模型在不同的数据集上表现一致。图11和图12显示,对于两个数据集,该模型的准确度优于其他两个单独模型所获得的准确度。
该模型还针对18个可用数据集中的其余数据集进行了测试,这些数据集总结在下表6中。
表6不同数据集的混合模型准确度
4.结论
股票市场预测分析是在20个样本上进行的,其中10个属于国家证券交易所,另外10个属于纽约证券交易所。平均而言,10年期间的股票价值由每个样本2300行组成。所考虑的时间区间为2006年-2016年和2010年-2020年。XGBoost模型与用于分析的20个样本是一致。XGBoost模型对NSE数据集的平均准确率为88.66,对NYSE数据集的平均准确率为90.11。尽管KalmanFilter统计模型产生了令人印象深刻的结果,但模型的准确性并不一致。KalmanFilter模型对NSE数据集的平均准确率为89.09,对NYSE数据集的平均准确率为64.96。混合模型似乎可以很准确地预测脚本的未来趋势,但它不能对所有样本都这样做。Hybrid模型对NSE数据集的平均准确率为76.79,对NYSE数据集的平均准确率为70.91。将每个季度的市场情绪添加到所有样本中,似乎可以提高三个模型的准确性。当数据集由更高价值的股票数据组成时,混合模型似乎优于其他两个模型。
5.未来
论文中描述的三个模型都给出了良好的准确度和一致的结果。但Hybrid模型在股票价值的未来预测方面是最好的,它预测了市场的高点和低点,并提高了效率。作为项目的未来工作,我们可以考虑一组样本来进行样本选择。然后,我们可以在这些样本上执行投资组合管理,其中模型返回所需的投资、可接受的风险和手头的投资金额。
6.参考文献:

这几年来,随着我国二胎家庭以及三胎家庭逐渐增多,不少消费对MPV车型有了更高的需求。而在火爆的MPV领域,我国自主品牌也是相当给力,给国内消费者留下深刻印象.
1900/1/1 0:00:00DAO的特点 分布式与去中心化 DAO中没有中心节点或分层管理结构。它通过网络节点间自底向上的交互、竞争和协作来实现组织目标.
1900/1/1 0:00:00自俄乌冲突以来,马斯克的“星链”卫星为乌军提供了通信支持,而美国更需要“星链”技术为其提供情报服务,一旦失去“星链”,乌克兰和美国都会有损失,将直接影响俄乌战局,但由于“星链”太烧钱.
1900/1/1 0:00:00山葵也叫做山萮菜、泽山葵、溪山葵等,它是一种绿色的高山植物。山葵有着特殊的香味及辣味,有点类似于辣根的味道,西方人叫山葵为日本芥末或者日本辣根.
1900/1/1 0:00:00谚云:开门七件事,柴米油盐酱醋茶。茶虽位列第七位,但能与柴米油盐相提并论,足见其在中国人心目中的地位。作为茶的故乡,中国人饮茶的历史由来已久.
1900/1/1 0:00:00最适合玩家的广告格式是什么?奖励视频广告。游戏发行商和广告商们都看重它。这种广告格式适用于许多不同的类型和游戏。造成这种情况的原因有很多,将在本文中解释所有这些原因.
1900/1/1 0:00:00