众所周知,OpenAI并不“open”,特别是在GPT-4发布后,整个OpenAI团队对GPT-4的几乎所有信息都守口如瓶。
而就在今天上午,媒体semianalysis的DylanPatel和GeraldWong发表了一篇题为《GPT-4Architecture,Infrastructure,TrainingDataset,Costs,Vision,MoE》的文章,曝光了GPT-4从模型架构、模型训练到成本的所有细节,GPT-4又被“开源”了?
文章中详细介绍了GPT-4的架构、训练和推理的基础设施、参数量、训练数据集、token数、成本、混合专家模型等非常具体的参数和信息。
同时还“深扒了”在不同的路线选择上,OpenAI面临的各类权衡,并直言,对GPT-4而言,最有趣的是理解OpenAI为什么会做出某些架构决策。

https://www.semianalysis.com/p/gpt-4-architecture-infrastructure值得注意的是,DylanPatel同样也是谷歌内部文件泄漏事件的作者。

而DeepMindCEOHassabis近日在接受媒体采访时,确认了这份谷歌被泄漏的文件的真实性。
鉴于爆料者是DylanPatel,此次GPT-4“大揭秘”的真实性又提高了几分。
文章开头就指出,OpenAI之所以不open,不是为了保护人类不被AI毁灭,而是因为他们构建的大模型是可复制的,未来中国和美国的互联网大厂及AI头部初创企业,都会有能力构建出可以和GPT-4媲美甚至超越GPT-4的大模型。
而OpenAI最持久的护城河,就在于他们拥有真实用户的使用反馈,业内最顶尖的工程人才,以及先发优势带来的领先地位。
华尔街见闻整理了关于GPT-4爆料的主要内容:
1.8万亿巨量参数和模型框架
文章指出,GPT-4在120层中总共包含了1.8万亿参数,而GPT-3只有约1750亿个参数。也就是说,GPT-4的规模是GPT-3的10倍以上。
OpenAI通过使用混合专家模型来控制成本。GPT-4拥有16个专家模型,每个MLP专家大约有1110亿个参数。其中,有两个专家模型被用于前向传播。
OpenAI用于GPT-4的算法,其实非常简单。模型中还有约550亿个参数,被用做注意力机制的共享。
每次的前向传播推理中,GPT-4只需要使用大约2800亿参数和560TFLOPs。相比之下,纯密集模型每次前向传播需要大约1.8万亿个参数和约3700TFLOP的计算量。
数据集的构成
OpenAI用13万亿的token训出了GPT-4。因为没有高质量的token,这个数据集还包含了许多个epoch。
Epoch数量:针对基于文本的数据进行2个epoch的训练,而针对基于代码的数据进行了4个epoch的训练。
在预训练阶段,GPT-4使用了8k的上下文长度,而32k的版本是基于预训练后的8K版本微调而来的。
在几天之内批大小在集群中逐渐增加。最终OpenAI使用的批大小达到了6000万,当然,由于并非每个专家模型都能看到所有token,因此这仅为每个750万token的专家模型的大小
OpenAI:ChatGPT安卓版现在可以在美国、印度、孟加拉国和巴西下载使用:7月25日消息,OpenAI表示,ChatGPT安卓版现在可以在美国、印度、孟加拉国和巴西下载使用。计划在下周将推广范围扩大到更多国家。[2023/7/26 15:58:22]
真实的批处理大小:将这个数字除以序列长度即可得到。
OpenAI的并行策略
并行策略对于A100GPU是相当重要的。为了在所有A100GPU上进行并行计算,OpenAI采用了8路张量并行,因为这是NVLink的极限。除此之外,据说OpenAI采用15路并行管线。
理论上,考虑到数据通信和计算时间,15个管线就有些多了。但是一旦加上了KV缓存和成本,如果OpenAI使用的GPU大部分是40GB的A100,那这样的构架在理论上就是有意义的。
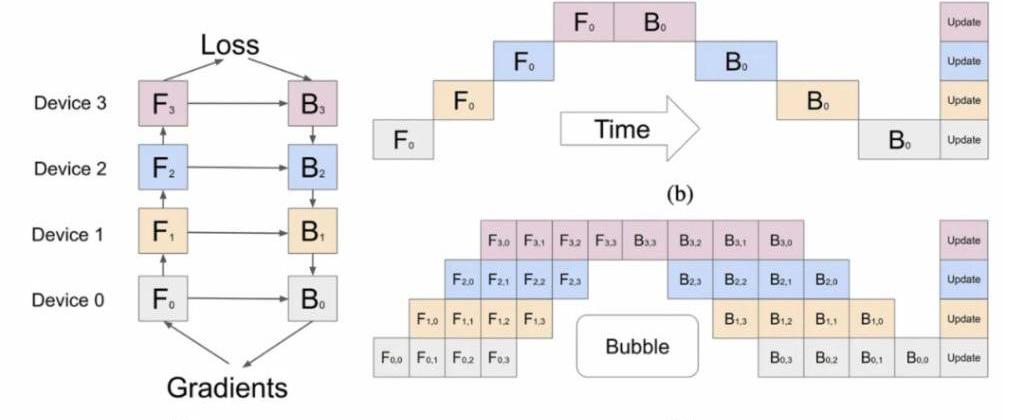
但作者表示,他并不是太明白OpenAI在如此高的管线并行度下,如何避免在每批中产生如下图这样的“泡泡”,很有可能OpenAI就是生生地抗下了这些成本。
训练成本:一次的训练的成本为6300万美元
OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,利用率在32%到36%之间。故障数量过多也是极低利用率的原因,这会导致需要重新从之前的检查点开始训练。
另一个原因是这么多GPU之间的all-reduce非常昂贵。
如果OpenAI云计算的成本是差不多1美元/每A100小时的话,那么在这样的条件下,仅这次训练的成本大约是6300万美元。
这还不包括所有的实验、失败的训练和其他成本,比如数据收集、RLHF、人力成本等。
如果考虑到刚刚说的这些因素,真实成本要高得多的多。
但是放到今天,在2美元/每H100小时的条件下,预训练可以在大约8192个H100上进行,只需要55天,费用为2150万美元。
使用专家混合模型时的权衡
MoE是一种在推理过程中减少参数量的很好方法,但同时他会增加参数量。
如果OpenAI真的想追求最佳性能,他们需要训练两倍的token才能达到。
采用相对比较少的专家模型的原因很多,OpenAI选择16个专家的原因之一在于,在执行许多任务上,更多的专家模型很难泛化,也更难实现收敛。
GPT-4推理成本
与拥有1750亿参数的Davinchi模型相比,GPT-4的成本是其3倍,尽管其前馈参数只增加了1.6倍。这主要是因为GPT-4需要更大的集群,并且实现的利用率更低。
作者认为,在用128个A100GPU进行推理的情况下,GPT-4的8k序列长度每1000个标记的成本为0.0049美元,而在128个H100上推理GPT-4的8k序列长度每1000个标记的成本为0.0021美元。
需要注意的是,这是假设有相当高的利用率,并保持较高批大小的情况下。但很明显,OpenAI有时的利用率非常低。
多查询注意力
OpenAI和其他大厂一样,也在使用MQA。
简单来说只需要一个注意力头,并且可以显著减少KV缓存的内存占用。即便如此,32k长度的GPT-4肯定无法在40GB的A100上运行,而8k的最大批大小也有上限。
Space and Time推出由ChatGPT支持的聊天机器人以提升产品体验:7月11日消息,去中心化数据初创公司 Space and Time 在微软风险投资部门和 Hashkey Capital 的支持下,已使用 OpenAI 的 GPT-4(ChatGPT 的最新版本)集成了一个聊天机器人——Houston,以便开发人员使用自然语言展开工作,更加轻松地维护和查询数据库。[2023/7/11 10:48:46]
连续批处理
OpenAI实现了可变批大小和连续批处理。
这样做是为了允许一定程度的最大延迟,并优化推理成本。
推测解码
OpenAI在GPT-4的推理过程中使用了“推测解码”。
“推测解码”的基本原理是使用一个更小、更快的草案模型提前解码多个token,然后将它们作为一个批输入到预测模型中。如果OpenAI使用“推测解码”,他们可能只在大约4个token的序列中使用。
视觉多模态
它是一个独立于文本编码器的视觉编码器,二者之间存在交叉注意力,该架构类似于Flamingo。这在GPT-4的1.8万亿个参数之上增加了更多参数。
GPT-4多模态能力是在文本预训练之后,又用大约2万亿token进?了微调。据称,在视觉模型上,OpenAI原本希望从头开始训练,但因其不够成熟,无奈从文本训练模型进行微调。
而下一代模型GPT-5,将从头开始进行视觉训练,并且也能自己生成图像,甚至生成音频。
以下为有新Newin通过GPT翻译的全文:
OpenAI保持GPT-4架构封闭,不是因为对人类的某种存在风险,而是因为他们所构建的内容是可复制的。实际上,我们预计Google、Meta、Anthropic、Inflection、Character、Tencent、ByteDance、Baidu等公司在短期内将拥有与GPT-4一样甚至更强大的模型能力。
请不要误解,OpenAI具有令人惊叹的工程能力,他们所构建的东西令人难以置信,但他们所找到的解决方案并非魔法。这是一个优雅的解决方案,其中包含许多复杂的权衡。规模扩大只是战斗的一部分。OpenAI最持久的竞争优势在于他们拥有最多的实际应用、领先的工程人才,并且可以通过未来的模型继续超越其他公司。
我们从多个来源收集了关于GPT-4的大量信息,今天我们想分享一下。这包括模型架构、训练基础设施、推理基础设施、参数数量、训练数据集组成、令牌数量、层数量、并行策略、多模态视觉适应、不同工程权衡背后的思考过程、实施的独特技术以及他们如何减轻与庞大模型推理相关的一些最大瓶颈。
GPT-4最有趣的方面是理解他们为什么做出某些架构决策。
此外,我们将概述在A100上训练和推理GPT-4的成本,以及在下一代模型架构中如何与H100进行扩展。
首先,让我们来看看问题陈述。从GPT-3到4,OpenAI希望扩大100倍,但问题是成本。密集的Transformer模型将无法进一步扩展。密集的Transformer是OpenAIGPT-3、GooglePaLM、MetaLLAMA、TIIFalcon、MosaicMLMPT等模型使用的模型架构。我们可以轻松地列举出使用这种相同架构训练LLM的50多家公司。这是一个不错的架构,但对于扩展来说有缺陷。
在GPT-4发布之前,我们曾讨论过训练成本与即将到来的AI砖墙之间的关系。在那里,我们揭示了OpenAI在GPT-4架构和各种现有模型的训练成本方面的高层次做法。
马云谈ChatGPT:要用人工智能去解决问题:3月27日消息,据云谷教育官微,马云表示,ChatGPT这一类技术已经对教育带来挑战,但是ChatGPT这一类技术只是AI时代的开始。我们要用人工智能去解决问题,而不是被人工智能所控制,虽然人的体力、脑力比不过机器,但机器只有“芯”,而人有“心”。注:云谷学校是阿里合伙人投资创办的民办学校。[2023/3/27 13:28:54]
在过去的六个月中,我们意识到训练成本是无关紧要的。
当然,表面上看起来很疯狂,要花费数千万甚至数亿美元的计算时间来训练一个模型,但对于这些公司来说,这是微不足道的开支。这实际上是一项固定资本支出,在扩大规模方面始终能够取得更好的结果。唯一的限制因素是将计算规模扩展到人类可以获得反馈并修改架构的时间尺度上。
在未来的几年里,像Google、Meta和OpenAI/Microsoft这样的多家公司将在价值超过一千亿美元的超级计算机上训练模型。Meta每年在"Metaverse"上烧掉160亿美元,Google每年在各种项目上浪费100亿美元,Amazon在Alexa上损失超过500亿美元,加密货币在毫无价值的事物上浪费了1000亿美元以上。
这些公司和整个社会可以并且将会在创建可以训练单个巨大模型的超级计算机上花费超过一千亿美元。然后,这些巨大的模型可以以多种方式成为产品。这项工作将在多个国家和公司中复制。这是一场新的太空竞赛。与以前的浪费不同,现在的人工智能具有实实在在的价值,短期内将从人类助手和自主代理中获得。
扩展人工智能更重要的问题是推理。
目标是将训练计算与推理计算分离。这就是为什么有意义的训练超出Chinchilla最佳的范围,无论将要部署的模型如何。这就是为什么要使用稀疏模型架构;在推理过程中,并不需要激活每个参数。
真正的挑战是将这些模型扩展到用户和代理的成本太高。推理的成本比训练的成本高出多倍。这是OpenAI在模型架构和基础设施方面的创新目标。
大型模型的推理是一个多变量问题,对于密集模型来说,模型大小是致命的。我们在这里详细讨论了与边缘计算相关的问题,但数据中心的问题陈述非常相似。简单来说,设备永远无法拥有足够的内存带宽来实现大语言模型的特定吞吐量水平。即使带宽足够,边缘计算设备上硬件计算资源的利用率也将非常低。
在数据中心、云端,利用率是至关重要的。Nvidia之所以因其卓越的软件而受到赞赏,其中一半的原因是因为在GPU的整个生命周期中,Nvidia不断更新低级别软件,通过更智能地在芯片内部、芯片之间和内存之间移动数据,将FLOPS的利用率提高。
在大多数当前使用案例中,LLM推理的目标是作为实时助手运行,这意味着它必须达到足够高的吞吐量,使用户能够真正使用它。人类平均阅读速度约为每分钟250个词,但有些人甚至高达每分钟1000个词。这意味着您需要至少每秒输出8.33个令牌,但更接近每秒输出33.33个令牌以应对所有情况。
根据内存带宽的要求,一个兆参数的密集模型在最新的NvidiaH100GPU服务器上数学上无法实现这种吞吐量。
每个生成的令牌都需要将每个参数从内存加载到芯片上。生成的令牌然后输入到提示中,并生成下一个令牌。此外,为注意力机制流式传输KV缓存还需要额外的带宽。
4训练成本
OpenAI在GPT-4的训练中,使用了大约25,000个A100芯片,在90至100天的时间内进行了约32%至36%的MFU。这种极低的利用率部分是由于大量的故障导致需要从检查点重新启动的原因,上述提到的气泡代价非常高。
字节AI实验室正开展类似ChatGPT和AIGC相关研发:金色财经报道,字节跳动的人工智能实验室(AI Lab)有开展类似ChatGPT和AIGC的相关研发,未来或为PICO提供技术支持。据知情人士透露,PICO目前的业务发展不及预期,为此字节AI Lab将在VR内容生成上开展更多探索。
据悉,字节AI Lab成立于2016年,研究领域主要涉及自然语言处理、数据挖掘、机器学习、语音与音频等。(科创板日报)[2023/2/9 11:56:36]
另一个原因是在这么多GPU之间进行全局归约的代价非常高。如果我们的猜测是正确的,那么该集群实际上是由许多较小的集群组成的,它们之间的网络连接非常薄弱,即集群的不同部分之间的非阻塞连接为800G/1.6T,但这些部分只能以200G/400G的速度连接起来。
如果他们在云中的成本约为每小时1美元的A100芯片,仅这次训练的成本就约为6300万美元。这还没有考虑到所有的实验、失败的训练运行和其他成本,比如数据收集、强化学习和人员成本等。由于这些因素,实际成本要高得多。此外,这意味着您需要有人购买芯片/网络/数据中心、承担资本支出并将其租给您。
目前,使用约8,192个H100芯片,以每小时2美元的价格,在约55天内可以完成预训练,成本约为2150万美元。需要注意的是,我们相信到今年年底将有9家公司将拥有更多的H100芯片。并非所有这些公司都会将它们全部用于单次训练运行,但那些这样做的公司将会拥有更大规模的模型。Meta将在今年年底拥有超过10万个H100芯片,但其中相当多的芯片将分布在他们的数据中心用于推理。他们最大的单个集群仍然将超过25,000个H100芯片。
到今年年底,很多公司将拥有足够的计算资源来训练与GPT-4规模相当的模型。
5MoE的权衡
在推理过程中,MoE是一种很好的方式,可以在推理时减少参数数量,同时增加参数数量,这对于编码更多的信息每个训练令牌是必需的,因为获取足够的高质量令牌非常困难。如果OpenAI真的试图实现Chinchilla最佳化,他们将不得不在训练中使用两倍于目前的令牌数量。
尽管如此,OpenAI做出了多个权衡。例如,在推理过程中,MoE非常难处理,因为模型的每个部分在每个令牌生成时都不会被使用。这意味着在为用户提供服务时,某些部分可能处于闲置状态,而其他部分则正在使用。这对利用率产生了很大的负面影响。
研究人员已经表明,使用64到128个专家比使用16个专家的损失更小,但那只是纯粹的研究结果。减少专家的数量有多个原因。OpenAI选择16个专家的原因之一是因为更多的专家在许多任务上很难进行泛化。使用更多的专家也可能更难实现收敛。在如此大规模的训练运行中,OpenAI选择在专家数量上更保守一些。
此外,减少专家的数量还有助于他们的推理基础设施。在采用专家混合推理架构时,存在各种困难的权衡。在探讨OpenAI面临的权衡和他们所做的选择之前,我们先从LLM的推理基本权衡开始。
6推理的权衡
顺便说一下,在开始之前,我们想指出,我们与所有LLM公司交谈过的人都认为Nvidia的FasterTransformer推理库相当糟糕,TensorRT则更糟。无法使用Nvidia的模板并进行修改的缺点意味着人们需要从零开始创建自己的解决方案。如果你是Nvidia的工作人员,阅读这篇文章后,你需要尽快解决这个问题,否则默认的选择将变为开放工具,这样第三方硬件支持可以更容易地添加进来。一波巨大的模型即将到来。如果在推理方面没有软件优势,并且仍然需要手工编写内核,那么AMD的MI300和其他硬件将有更大的市场。
?ChatGPT概念继续走强:2月6日消息,ChatGPT概念股继续走强,科创板海天瑞声再度触及涨停,近6个交易日股价翻倍。汉王科技、天娱数科、高鸿股份等涨停,福石控股、拓尔思、云从科技等继续走高。[2023/2/6 11:49:40]
在大型语言模型的推理中,有3个主要的权衡,它们发生在批量大小和使用的芯片数量之间。
延迟-模型必须以合理的延迟做出响应。人们不想在等待输出开始流入聊天应用程序之前等待几秒钟。预加载和解码需要不同的时间来处理。吞吐量-模型必须以每秒输出一定数量的令牌。大约每秒30个令牌是人类使用所需的。对于其他各种用途,较低和较高的吞吐量都可以接受。利用率-运行模型的硬件必须实现高利用率,否则成本将过高。虽然可以使用更高的延迟和较低的吞吐量将更多用户请求进行分组,从而实现更高的利用率,但这会增加难度。LLM的推理完全是关于平衡两个主要因素:内存带宽和计算。在最过度简化的术语中,每个参数都必须读取,并且与之相关联的是2个FLOP。因此,大多数芯片的比例在批量大小为1的推理中完全不平衡。如果只为一个用户提供服务,批量大小为1,那么为了每个令牌生成,所需的内存带宽主导推理时间。计算时间几乎为零。为了有效地将大型语言模型扩展到多个用户,批量大小必须超过4。多个用户会分摊参数读取的成本。例如,对于批量大小为256或512,每个字节的内存读取有512个FLOP/s或1024个FLOP/s。
这个比例更接近于H100的内存带宽与FLOPS之间的比例。这有助于实现更高的利用率,但代价是更高的延迟。
许多人将内存容量视为LLM推理的一个主要瓶颈,原因是大型模型需要多个芯片进行推理,而较大的内存容量会使其适应的芯片数量减少,但实际上,最好使用超过所需容量的芯片,以便将延迟降低,提高吞吐量,并且可以使用更大的批量大小来实现越来越高的利用率。
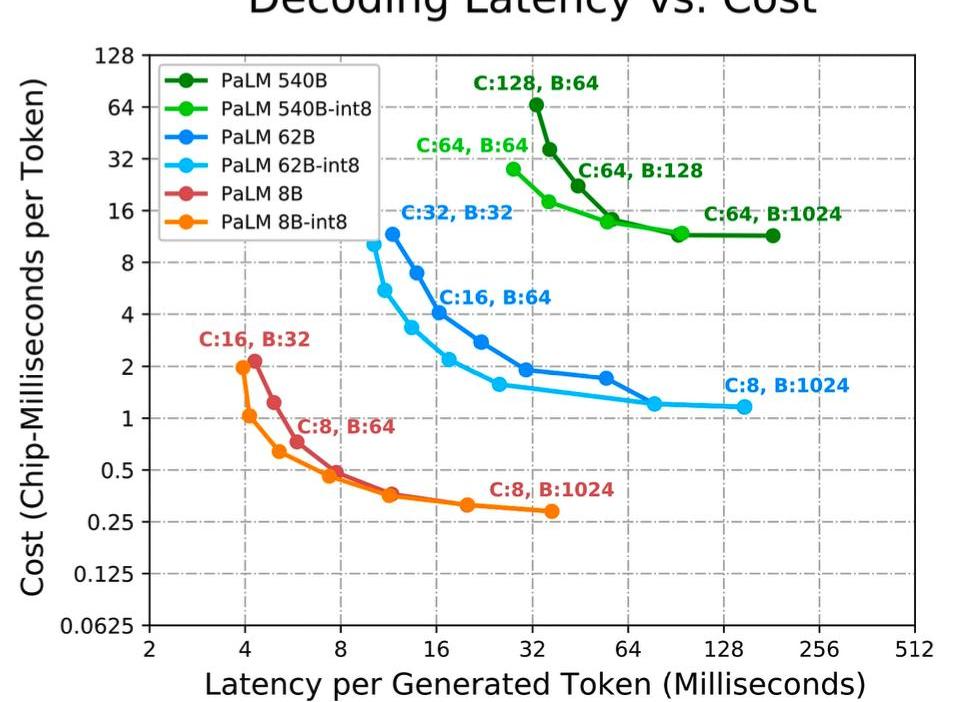
谷歌在他们的PaLM推理论文中展示了这些权衡。然而,值得注意的是,这是针对像PaLM这样的稠密模型,而不是像GPT-4这样的稀疏模型。
如果一个应用程序要求最低的延迟,我们需要应用更多的芯片,并将模型划分为尽可能多的部分。较小的批量大小通常可以实现较低的延迟,但较小的批量大小也会导致更差的利用率,从而导致每个令牌的总成本更高。如果一个应用程序需要离线推理,并且延迟不是问题,主要目标是最大化每个芯片的吞吐量。
增加批量大小是最高效的,因为较大的批量通常可以实现更好的利用率,但某些对于小批量大小来说不高效的划分策略在批量大小增大时变得高效起来。更多的芯片和更高的批量大小是最便宜的,因为它们可以增加利用率,但这也引入了一个第三个变量,即网络时间。某些将模型分割到不同芯片上的方法对于延迟更高效,但与利用率相互制衡。
内存时间和非注意计算时间都与模型大小成正比,与芯片数量成反比。然而,对于给定的分区布局,芯片间通信所需的时间下降得较慢,因此随着芯片数量的增加,它变得越来越重要,成为一个越来越重要的瓶颈。虽然我们今天只是简单地讨论一下,但应该注意到,随着批量大小和序列长度的增长,KV缓存的内存需求会急剧增加。如果一个应用程序需要生成具有较长注意力上下文的文本,则推理时间会显著增加。
对于一个具有多头注意力的500B+模型,注意力KV缓存会变得很大:对于批量大小为512和上下文长度为2048,KV缓存总共达到3TB,这是模型参数大小的3倍。芯片上的内存需要将此KV缓存从芯片外存加载到内存中,而此期间芯片的计算核心基本上处于闲置状态。较长的序列长度对内存带宽和内存容量特别不利。OpenAI的16k序列长度GPT3.5turbo和32k序列长度GPT4的成本要高得多,因为由于内存限制,它们无法使用更大的批量大小。
较低的批量大小导致较低的硬件利用率。此外,随着序列长度的增加,KV缓存也会变得更大。KV缓存无法在用户之间共享,因此需要单独的内存读取,进一步成为内存带宽的瓶颈。
7GPT-4的推理权衡和基础设施
以上所有内容在GPT-4推理中都很困难,但是模型架构采用了专家混合模型,这引入了一整套新的困难。每个令牌生成的前向传递可以路由到不同的专家集合中。这对于在批量大小较大时在吞吐量、延迟和利用率之间实现的权衡造成了困扰。
OpenAI的GPT-4有16个专家,每个前向传递中有2个专家。这意味着如果批量大小为8,每个专家的参数读取可能只是批量大小为1。更糟糕的是,可能一个专家的批量大小为8,而其他的专家可能是4、1或0。每次令牌生成,路由算法都会将前向传递发送到不同的方向,导致令牌到令牌的延迟以及专家批量大小的显著变化。推理基础设施是OpenAI选择较少的专家数量的主要原因之一。如果他们选择了更多的专家,内存带宽将更加成为推理的瓶颈。
OpenAI在推理集群上经常达到4k+的批量大小,这意味着即使在专家之间进行了最佳的负载均衡,专家的批量大小也只有约500个。这需要非常大量的使用才能实现。我们了解到,OpenAI在一个由128个GPU组成的集群上运行推理。他们在多个数据中心和地理位置上都有多个这样的集群。推理是在8路张量并行和16路流水线并行上进行的。每个由8个GPU组成的节点只有大约130B的参数,即每个GPU在FP16模式下不到30GB,在FP8/int8模式下不到15GB。这使得推理可以在40GB的A100芯片上运行,前提是所有批次的KV缓存大小不会过大。
包含各种专家的单个层不会分割到不同的节点上,因为这会使网络流量过于不规则,并且在每个令牌生成之间重新计算KV缓存的代价太高。对于任何未来的MoE模型扩展和条件路由,如何处理KV缓存的路由是一个最大的困难。
模型有120个层,所以将其平均分配到15个不同的节点上是很简单的,但由于第一个节点需要进行数据加载和嵌入,所以在推理集群的主节点上放置较少的层是有意义的。此外,我们听到了一些关于推理的猜测解码的传言,我们稍后会讨论,但我们不确定是否相信这些传言。这也可以解释为什么主节点需要包含较少的层。
8GPT-4的推理成本
与175B参数的Davinchi模型相比,GPT-4的成本是其3倍,尽管其前馈参数只增加了1.6倍。这主要是因为GPT-4需要更大的集群并实现了更低的利用率。
我们认为,对于128个A100来推理GPT-48k序列长度,每1k令牌的成本是0.0049美分,而对于128个H100来推理GPT-48k序列长度,每1k令牌的成本是0.0021美分。
值得注意的是,我们假设有较高的利用率,并保持较高的批量大小。这可能是一个错误的假设,因为很明显OpenAI有时的利用率非常低。我们假设OpenAI在低谷时段关闭集群,并重新调整这些节点以从检查点恢复对较小测试模型的训练,尝试各种新技术。这有助于降低推理成本。如果OpenAI不这样做,他们的利用率将更低,我们的成本估计将增加一倍以上。
9多查询注意力
MQA是其他公司正在使用的技术,但我们想指出OpenAI也在使用。长话短说,只需要一个头部,KV缓存的内存容量可以大大减少。即使如此,32k序列长度的GPT-4肯定无法在40GB的A100芯片上运行,而8k序列长度的GPT-4在最大批量大小上受到限制。如果没有MQA,8k序列长度的GPT-4的最大批量大小将受到极大的限制,以至于经济上不可行。
10连续批处理
OpenAI实现了可变的批量大小和连续批处理。这样可以在一定程度上允许最大延迟,并优化推理成本。如果您对这个概念不熟悉,那么这篇由AnyScale撰写的文章值得一读。
11关于猜测解
我们从一些可靠的人士那里听说OpenAI在GPT-4推理中使用了猜测解码。我们不确定是否完全相信这一点。令牌到令牌的延迟的普遍变化以及在进行简单的检索任务与更复杂的任务时的差异似乎表明这是可能的,但是变量太多,无法确定。以防万一,我们将在这里使用一些“使用分段猜测解码加速LLM推理”的文本并稍作修改/添加一些说明。
使用LLM通常分为两个阶段。首先是预填充阶段,将提示文本通过模型生成KV缓存和第一个输出的logits。通常,这个阶段很快,因为整个提示文本可以并行处理。
第二阶段是解码。从输出的logits中选择一个令牌,并将其反馈到模型中,生成下一个令牌的logits。重复这个过程,直到生成所需数量的令牌。因为解码必须按顺序进行,每次都要将权重流通过计算单元以生成单个令牌,所以当以小批量运行时,第二阶段的算术强度非常低。
因此,解码通常是自回归生成中最昂贵的部分。这就是为什么在OpenAI的API调用中,输入令牌比输出令牌便宜得多的原因。
猜测解码的基本思想是使用一个更小、更快的草稿模型预先解码多个令牌,然后将它们作为一个批次馈送给神谕模型。如果草稿模型对其预测的令牌是正确的,即较大模型也同意,那么可以通过一个批次解码多个令牌,这样可以节省相当多的内存带宽和时间,每个令牌都能节省。
然而,如果较大模型拒绝了草稿模型预测的令牌,那么剩下的批次将被丢弃,算法自然会恢复到标准的逐令牌解码。猜测解码可能还伴随着拒绝采样方案,以从原始分布中进行采样。请注意,这仅在带宽是瓶颈的小批量设置中有用。
猜测解码通过交换计算和带宽来进行权衡。猜测解码作为性能优化目标具有两个关键原因。首先,它完全不会降低模型质量。其次,它提供的优势通常与其他方法无关,因为其性能来自将顺序执行转换为并行执行。
目前的猜测方法为批次预测一个单独的序列。然而,这在大批量大小或低草稿模型对齐度的情况下无法很好地扩展。直观地说,两个模型在连续的长序列中达成一致的概率指数级地降低,这意味着随着算术强度的扩大,猜测解码的回报迅速减少。
我们认为如果OpenAI使用猜测解码,他们可能只在大约4个令牌的序列上使用它。顺便提一下,GPT-4降低质量的整个阴谋可能只是因为他们让神谕模型接受来自猜测解码模型的较低概率序列。另一个注意的是,有人猜测Bard使用了猜测解码,因为谷歌在将整个序列发送给用户之前等待序列的生成完成,但我们不相信这种猜测是真实的。
12关于视觉多模态
视觉多模态能力是GPT-4中最不令人印象深刻的部分,至少与领先的研究相比。当然,还没有任何公司将多模态LLM的研究商业化。
它是一个独立的视觉编码器,与文本编码器分开,但存在交叉注意力。我们听说它的架构类似于Flamingo。这在GPT-4的1.8T参数之上增加了更多的参数。在仅文本预训练之后,它还进行了另外约2万亿个令牌的微调。
对于视觉模型,OpenAI原本希望从头开始训练,但这种方法还不够成熟,因此他们决定先从文本开始以减轻风险。
据称,下一个模型GPT-5将从头开始进行视觉训练,并且能够自己生成图像。此外,它还将能够处理音频。
这种视觉能力的主要目的之一是让自主代理能够阅读网页并转录图像和视频中的内容。他们训练的数据中有一部分是联合数据、网页的屏幕截图、YouTube视频:采样帧,并运行Whisper来获取转录。
关于所有这些针对LLM的过度优化的有趣之处在于,视觉模型的成本与文本模型的成本不同。正如我们在“亚马逊云危机”文章中所描述的那样,在文本模型中,成本非常低。而在视觉模型中,数据加载的IO要高出约150倍。每个令牌的字节数为600,而不是文本的4。有很多关于图像压缩的研究正在进行中。
这对于那些正在根据未来2-3年内LLM的用例和比率来优化硬件的硬件供应商来说非常重要。他们可能会发现自己处于一个每个模型都具有强大的视觉和音频能力的世界中。他们可能会发现他们的架构适应不良。总的来说,架构肯定会发展到超越当前简化的基于文本的密集和/或MoE模型的阶段。
本文转自; 本报北京7月11日电中国人民银行发布的最新数据显示,今年上半年,我国人民币贷款增加15.73万亿元,同比多增2.02万亿元.
1900/1/1 0:00:00图为6月30日在阿根廷首都布宜诺斯艾利斯拍摄的阿根廷中央银行。马丁·萨巴拉摄目前,人民币已成为阿根廷重要的计价、结算、交易和储备货币之一.
1900/1/1 0:00:00全文共1545字,阅读时间约为3分钟。在当今数字时代,区块链技术的兴起正逐渐改变着经济和社会的格局。区块链技术以其去中心化、不可篡改的特性,赋予了我们建立可信任环境的能力.
1900/1/1 0:00:007月11日,三家移动运营商正式上线数字硬钱包。中国银行、中国电信、中国联通在数字人民币App联合上线SIM卡硬钱包产品.
1900/1/1 0:00:00近日,随着恒力石化子公司康辉新材分拆“借壳”大连热电的方案出炉,恒力石化实控人陈建华、范红卫的A股版图将再度得到拓展,构建出3家A股公司+1家新三板公司的资本版图.
1900/1/1 0:00:00小米智能生态宣布,米家冰箱四大系列:自由嵌入系列、冰晶白系列、冰晶岩系列、巨能装系列至高优惠850元,活动截至7月31日,活动会场点此进入.
1900/1/1 0:00:00