撰文:TanyaMalhotra
来源:Marktechpost
编译:DeFi之道

图片来源:由无界版图AI工具生成
随着生成性人工智能在过去几个月的巨大成功,大型语言模型正在不断改进。这些模型正在为一些值得注意的经济和社会转型做出贡献。OpenAI开发的ChatGPT是一个自然语言处理模型,允许用户生成有意义的文本。不仅如此,它还可以回答问题,总结长段落,编写代码和电子邮件等。其他语言模型,如Pathways语言模型、Chinchilla等,在模仿人类方面也有很好的表现。
区块链能源交易平台UrbanChain完成525万英镑A轮融资,Eurazeo领投:5月25日消息,区块链能源交易平台 UrbanChain 宣布完成 525 万英镑 A 轮融资,Eurazeo 领投。UrbanChain 目前在英国运行一个 P2P 能源交易平台,该平台利用区块链和人工智能系统对再生能源发电商和消费者进行匹配,让用户获得合理的电价服务,继而降低企业和家庭的电费账单。[2023/5/25 10:39:53]
大型语言模型使用强化学习来进行微调。强化学习是一种基于奖励系统的反馈驱动的机器学习方法。代理通过完成某些任务并观察这些行动的结果来学习在一个环境中的表现。代理在很好地完成一个任务后会得到积极的反馈,而完成地不好则会有相应的惩罚。像ChatGPT这样的LLM表现出的卓越性能都要归功于强化学习。
Michael Novogratz:BTC牛市即将到来:金色财经报道,Galaxy Digital首席执行官Michael Novogratz在最近的讨论中表示,最清晰的交易将是继续做多黄金、做多欧元、做多比特币和做多以太坊。这些资产应该在美联储停止加息然后降息的情况下表现良好。在 2023 年的最后几个月,比特币的价格将达到约 4 万美元,最终将为加密货币领域增加约 2000 亿美元。[2023/5/23 15:19:55]
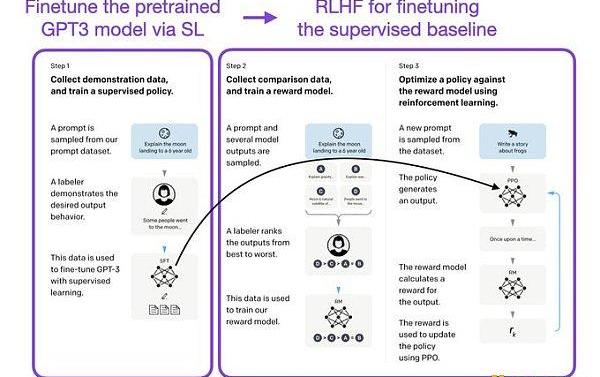
ChatGPT使用来自人类反馈的强化学习,通过最小化偏差对模型进行微调。但为什么不是监督学习呢?一个基本的强化学习范式由用于训练模型的标签组成。但是为什么这些标签不能直接用于监督学习方法呢?人工智能和机器学习研究员SebastianRaschka在他的推特上分享了一些原因,即为什么强化学习被用于微调而不是监督学习。
Polygon 前东南亚区负责人 Charlie 加入 Syscoin 任顾问:2月11日消息,前Polygon东南亚区负责人Charlie Hu加入Syscoin。fxempire新闻稿称,Charlie 将成为Syscoin向未开发市场扩张的关键人物,其将担任这方面的专家顾问。
Charlie 因其在区块链行业的经验以及他在WEB3.0和去中心化应用(dApps)方面的知识经验而闻名。在Polygon工作期间,Charlie 负责推动Polygon生态系统的发展、业务增长。
Charlie 表示,“不得不提到Syscoin的巨大上升潜力,不能低估这个项目通过解决问题为整个空间提供价值的能力,这将让底层技术得到真正大规模采用。这并不是财务建议,但像Syscoin这样的项目仍然被低估,能加入他们的团队感到非常荣幸。”
据悉,Syscoin,起步于2014年,其开发目的是将比特币和以太坊的优势发挥出来,以便为其用户提供一个安全可靠的网络,其借助ZK-Rollups,进一步增加了其扩展网络能力。[2022/2/11 9:45:07]
OKExChain将于4月25日16时进行主网升级:据官方公告,OKExChain将于2021年4月25日16:00进行主网升级,届时将暂停链上交易。升级完毕后OKExChain除原有的ex前缀地址格式外,还将支持0x地址格式。[2021/4/24 20:53:40]
不使用监督学习的第一个原因是,它只预测等级,不会产生连贯的反应;该模型只是学习给与训练集相似的反应打上高分,即使它们是不连贯的。另一方面,RLHF则被训练来估计产生反应的质量,而不仅仅是排名分数。
SebastianRaschka分享了使用监督学习将任务重新表述为一个受限的优化问题的想法。损失函数结合了输出文本损失和奖励分数项。这将使生成的响应和排名的质量更高。但这种方法只有在目标正确产生问题-答案对时才能成功。但是累积奖励对于实现用户和ChatGPT之间的连贯对话也是必要的,而监督学习无法提供这种奖励。
不选择SL的第三个原因是,它使用交叉熵来优化标记级的损失。虽然在文本段落的标记水平上,改变反应中的个别单词可能对整体损失只有很小的影响,但如果一个单词被否定,产生连贯性对话的复杂任务可能会完全改变上下文。因此,仅仅依靠SL是不够的,RLHF对于考虑整个对话的背景和连贯性是必要的。
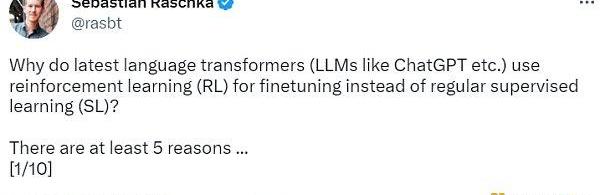
监督学习可以用来训练一个模型,但根据经验发现RLHF往往表现得更好。2022年的一篇论文《从人类反馈中学习总结》显示,RLHF比SL表现得更好。原因是RLHF考虑了连贯性对话的累积奖励,而SL由于其文本段落级的损失函数而未能很好做到这一点。
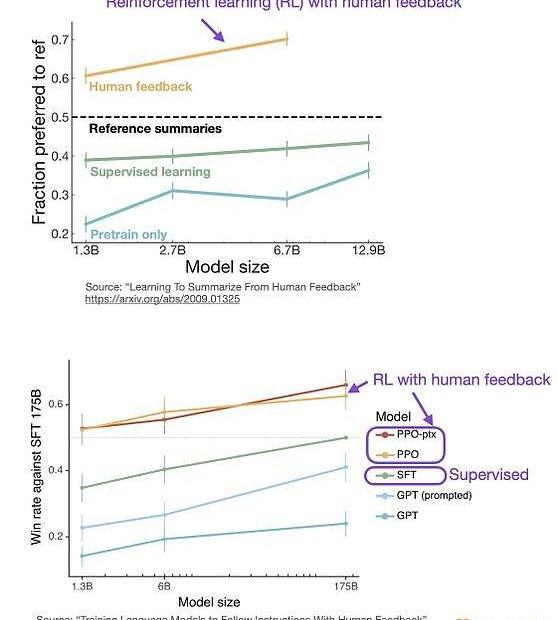
像InstructGPT和ChatGPT这样的LLMs同时使用监督学习和强化学习。这两者的结合对于实现最佳性能至关重要。在这些模型中,首先使用SL对模型进行微调,然后使用RL进一步更新。SL阶段允许模型学习任务的基本结构和内容,而RLHF阶段则完善模型的反应以提高准确性。
DeFi数据1、DeFi代币总市值:503.3亿美元 DeFi总市值及前十代币数据来源:coingecko2、过去24小时去中心化交易所的交易量47.
1900/1/1 0:00:00ZK作为L2、隐私、跨链等概念下的核心技术派系,该板块热度自2022年延续至今;近期的?ETHdenver大会上,ZK持续高热.
1900/1/1 0:00:00今天凌晨,?Sui开发团队MystenLabs在官方推特上举办了主题为「TheWavetoMainnet」的TwitterSpace.
1900/1/1 0:00:00作者:木遥,来源:作者微博你可能已经看到ChatGPT今天宣布推出插件功能的新闻了。这可能是近期一系列进展中最令人惊讶和震撼的一个.
1900/1/1 0:00:00一道难题摆在鲍威尔和美联储面前:加息or不加息——加息将加速银行业危机的蔓延,但若不加息或降息,又将放任仍然高涨的通胀.
1900/1/1 0:00:00作者:北京大学国家发展研究院研究员何小贝这是一起区域性中小银行引发的全球系统性金融风险事件。硅谷银行和签字银行以资产规模而言在美国银行中分别仅排16和29,且与大型银行的规模相去甚远,但却引发了.
1900/1/1 0:00:00